
Teaching AI to See: A Technical Deep-Dive on Vision Language Models with Will Hardman of Veratai

In this episode of The Cognitive Revolution, Nathan hosts Will Hardman, founder of AI advisory firm Veritai, for a comprehensive technical survey of vision language models (VLMs).
Watch Episode Here
Read Episode Description
In this episode of The Cognitive Revolution, Nathan hosts Will Hardman, founder of AI advisory firm Veritai, for a comprehensive technical survey of vision language models (VLMs). We explore the evolution from early vision transformers to state-of-the-art architectures like InternVL and Llama3V, examining key innovations and architectural decisions. Join us for an in-depth discussion covering multimodality in AI systems, evaluation frameworks, and practical applications with one of the field's leading experts.
Help shape our show by taking our quick listener survey at https://bit.ly/TurpentinePulse
SPONSORS:
Oracle Cloud Infrastructure (OCI): Oracle's next-generation cloud platform delivers blazing-fast AI and ML performance with 50% less for compute and 80% less for outbound networking compared to other cloud providers. OCI powers industry leaders like Vodafone and Thomson Reuters with secure infrastructure and application development capabilities. New U.S. customers can get their cloud bill cut in half by switching to OCI before March 31, 2024 at https://oracle.com/cognitive
80,000 Hours: 80,000 Hours is dedicated to helping you find a fulfilling career that makes a difference. With nearly a decade of research, they offer in-depth material on AI risks, AI policy, and AI safety research. Explore their articles, career reviews, and a podcast featuring experts like Anthropic CEO Dario Amodei. Everything is free, including their Career Guide. Visit https://80000hours.org/cogniti... to start making a meaningful impact today.
CHAPTERS:
(00:00:00) Teaser
(00:00:55) About the Episode
(00:05:45) Introduction
(00:09:16) VLM Use Cases
(00:13:47) Vision Transformers (Part 1)
(00:17:48) Sponsors: Oracle Cloud Infrastructure (OCI)
(00:19:00) Vision Transformers (Part 2)
(00:24:58) OpenAI's CLIP Model
(00:33:44) DeepMind's Flamingo (Part 1)
(00:33:44) Sponsors: 80,000 Hours
(00:35:17) DeepMind's Flamingo (Part 2)
(00:48:29) Instruction Tuning with LAVA
(01:09:25) MMMU Benchmark
(01:14:42) Pre-training with QNVL
(01:32:13) InternVL Model Series
(01:52:33) Cross-Attention vs. Self-Attention
(02:14:33) Hybrid Architectures
(02:31:08) Early vs. Late Fusion
(02:34:50) VQA and DocVQA Benchmarks
(02:40:08) The Blink Benchmark
(03:05:37) Generative Pre-training
(03:15:26) Multimodal Generation
(03:37:00) Frontier Labs & Benchmarks
(03:47:45) Conclusion
(03:53:28) Outro
SOCIAL LINKS:
Website: https://www.cognitiverevolutio...
Twitter (Podcast): https://x.com/cogrev_podcast
Twitter (Nathan): https://x.com/labenz
LinkedIn: https://www.linkedin.com/in/na...
Youtube: https://www.youtube.com/@Cogni...
Apple: https://podcasts.apple.com/de/...
Spotify: https://open.spotify.com/show/...
Vision Language Models
Preface
- We’re aiming to provide an introduction to multi-modal AI - specifically for Vision-Language Models (VLMs).
- This is a “deep dive” from the perspective of someone with a general interest in AI, but it’s really just an introduction to a deep and complex field of vision-language models
- So, we’ll assume familiarity with the general field of LLMs and deep learning but little in the specific area of multi-modal models.
- We can’t possibly provide a paper-by-paper analysis of the field - which is both deep and accelerating, so we’ll try to cover:
- An overview of the most important architectures and trends in research, illustrated via notable models - models anyone building in this space is likely to encounter.
- We’ll touch on the key datasets and benchmarks
- Then we’ll briefly examine recent attempts at “true” multi-modality (MM production as well as ingestion)
- Finally, we’ll look at how the best-in-class models compare
Motivation
- Many obvious use cases for VLMs - medical assistants, content filtering, media content indexing, managing large product catalogues, damage assessment in cars, etc
- Two further reasons being interested in VLMs: one obvious, one less so.
VLMs allow us to explore modality alignment
- In learning how to construct VLMs, we learn a lot about how to build the true, multi-modal models of the future - integrating further domains like audio, touch, LIDAR, etc
- Think about robotics: the range of sensory inputs that need to be integrated to cook a meal or perform a medical procedure.
MM Understanding may be important for AGI
The arguments for
- The human brain uses cross-modal integrated information to determine which concepts are activated. E.G. the McGurk effect
- The centrality of multi-sensory exploration to concept learning in infants was argued by Piaget.
- In deep learning, there are theoretical results demonstrating that latent embeddings generated from multi-modal data are of higher quality than those from single-modality (see here).
- Some researchers draw inspiration from Grounded Cognition Theory to argue for the importance of multi-modality in AI. (Note that current LMMs do not truly implement grounded cognition as described by the theory.)
The arguments against
- Frontier LLMs already show evidence of high-level abstraction, world models and sophisticated reasoning. There’s no obvious ceiling on performance in view as of today.
Vision Language Models
- If we’re Googling…:
- Large multi-modal model (LMM) and Multi-modal Large Language Model (MM-LMM or MLLM) generally mean the same thing.
- Vision-Language Models (VLMs) generally mean LLMs with image (and often video) understanding capabilities.
- VLMs are where most research has occurred to date. Some recent VLM architectures can natively generate image outputs also.
Vision Transformers
- The two minute overview.
- Introduced in 2020 by a team from Google, the canonical paper is An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Previously, most vision models had been based on CNNs, where stacks of convolutional filters learned to extract successively more global features from images.
- The idea was to see whether the vanilla transformer architecture (without any of the inductive biases of a CNN) could learn to extract the features from an image.
- The recipe is as follows:
- Divide the image into patches (originally of 16x16).
- Apply a (trainable) linearizing embedding to each patch to yield a “token”
- Feed the sequence of patches into a transformer encoder, using full attention
- Like BERT - add a [CLS] token and train the ViT on an image classification objective.
- Key finding: with scale, the transformer architecture beats CNNs.
- Note that input image resolution is fixed by design - 224 x 224 in the original paper
- If this were a LM encoder, normal practise would be to apply a pooling operation over the hidden states to extract an embedding vector
- However, for VLMs, normal practise is to extract the entire sequence of hidden states as this has been found to work better. For a resolution of 224x224 and patch size of 16x16 this would yield 196 visual tokens.
- When we come across a ViT, it’s name will tell us specifics about the architecture, for example, ViT-H/16 is a “Huge” ViT - which translates to 600M parameters, with a patch size of 16.
Aligning images and Text: CLIP from OpenAI (2021)
- Learning Transferable Visual Models From Natural Language Supervision
- CLIP stands for Contrastive Language-Image Pre-training
- A canonical model in the field which demonstrates how to align image and text encodings.
- Starting with a vision encoder (e.g. a ViT), a text encoder and a large dataset of (image, caption) pairs scraped from the web…
- jointly train the encoders so that they generate embedding vectors with high cosine similarity between an image and its caption.
- There is a simple linear projection added to each encoder to ensure that they project to an embedding space with conforming dimensions
- This is achieved using a contrastive loss mechanism. Within a batch of N (image, caption) pairs, the loss function penalises similarity between the N^2-N incorrect pairings and dissimilarity between the N correct pairings.
- Once trained, you can use CLIP for image search and other applications.
- It’s not, of course a generative model - but it does illustrate some of the important concepts we’ll cover later on.
The Cross-Attention Architecture: DeepMind’s Flamingo (2022)
- We’ll start with one of the most cited papers in MM research - and a foundational contribution to VLM research.
- The basic pattern, which we’ll see throughout this episode, is that the two modalities are encoded modalities separately - using an image encoder and a text tokenizer
- Then, you design a mechanism to align the two representations so that a LM “backbone” can attend to the visual tokens as it decodes.
- Constructed from a frozen, pre-trained ResNet F6 model (a CNN - not a ViT) and a frozen Chinchilla LM.
- The visual tokens are injected into the frozen LM via learnable, gated cross-attention layers sandwiched between its layers.
- This is cool, because we can freeze the image encoder and the rest of the LM and just train the newly initialised cross-attention layers.
- However, the set-up poses to two challenges:
- Firstly, how can you handle a variable number of images (leading to varying numbers of image tokens) be projected to into a fixed dimensionality?
- How can the large number of visual tokens be reduced, in turn reducing the number of trainable cross-attention parameters?
- Answer: by passing the encoded images are into a Perceiver Resampler (PR) module:
- This module is capable of “selecting” the most critical information out of a long sequence of input tokens without needing to compute a full all-to-all query-key matrix in the attention mechanism.
- This is a achieved by learning a low-dimensional, latent query vector to be used in the module’s attention mechanism, rather than using a projection of the inputs.
- If we have N visual tokens and L learnable queries then this attention mechanism is only O(N x L) and there are only L output tokens. Flamingo sets L = 64
- The PR module can contain >1 layers, with the visual tokens concatenated onto the attention vector each time
- It is effectively resampling the visual tokens, learning what features it needs to query from them during training.
- It’s now easy to see how the cross-attention layers inserted into the LM backbone can learn to effectively query these fixed-size image representations.
- The PR module therefore facilitates an arbitrary number of images (e.g. video frames) to be incorporated into a Flamingo prompt with a consistent and parsimonious image representation.
- To interleave images & text in an input, images are replaced by special tokens, which in turn prompt the decoder to attend to the encoding of the associated image.
- Training data:
- They use the ALIGN dataset, composed of 1.8 billion images paired with alt-texts
- In the ablations, they highlight the importance of interleaved data, collecting the MultiModal MassiveWeb (M3W) dataset.
- extracted from the HTML of approximately 43 million webpages, determining the positions of images relative to the text based on the Document Object Model.
- Sample evaluation tasks included captioning, VQA and OCR
- Works best in a few-shot setting. Very compute-efficient training (once the LM and vision encoder are done) and yet still competitive with task-specific models (as of 2022)
- The basic pattern of using cross-attention layers to integrate the modalities has been used by other teams since.
- What do we learn from this example?
- The cross-attention architecture enables us to freeze a LM backbone and train only the new, cross-attention layers. This is efficient.
- Furthermore, reducing the number of visual tokens using a PR leads to fewer trainable parameters.
- Flamingo team concentrated on architecture and efficient pre-training. For LLMs, it is common to also perform instruction-tuning. How does this work for VLMs?
Instruction Tuning VLMs: Example Model: LLaVA (2023)
- Large Language and Vision Assistant
- Papers for the LLaVA series of models, the original from a mixed Microsoft, academic team
- LLaVA: Visual Instruction Tuning
- LLaVA 1.5: [Improved Baselines with Visual Instruction Tuning](Improved Baselines with Visual Instruction Tuning)
- There’s no LLaVA-NExT paper but the repo is here: https://llava-vl.github.io/blog/2024-01-30-llava-next/
- LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
- Video Instruction Tuning With Synthetic Data (a.k.a. LLaVA Video)
- LLaVA-OneVision-72B
- Instruction tuning works well for increasing task competency and diversity for LLMs. Could scaling instruction-tuning serve a similar purpose for LMMs?
- First off, architecture of the original LLaVA:
- Base modules are a CLIP ViT-L/14 (2021 vintage) encoder and a Vicuna 13B decoder.
- Instead of using the cross-attention architecture, the LLaVA team chose a different approach, a simplification of one pioneered by the BLIP series of VLMs from SalesForce:
- Because the vision encoder is taken from a CLIP model, has already been aligned with language embeddings.
- Therefore, it should suffice to train a simple projection matrix align to simply adjust the alignment to work with a different LM - e.g. Vicuna.
- The visual ”tokens” (note - continuous not discrete) are then prepended to the text tokens
- Conceptually, this is similar to prefix-tuning (soft prompting) in LLMs.
- This approach is called the self-attention or auto-regressive VLM architecture.
- Note that this could potentially result in a long sequence of visual tokens since, unlike Flamingo, no resampling takes place.
- The pre-pending recipe lends itself well to a use case where there is a single, static image and a dialogue flow about that image.
- Conversely, it doesn’t support the arbitrary interleaving of images and text in the inputs, nor the use of multiple images.
- N.B. this restriction was been lifted by a later in the series - LLaVA-NExT-Interleave (same recipe, different team - this one from Bytedance)
- This recipe is more parameter efficient than the cross-attention architecture as only the projection matrix is updated during alignment pre-training.
- Key contribution: how to generate high-quality instruction-following data when it is scarce?
- Use the textual content associated with MS COCO images: i.e. the descriptions + labelled bounding boxes
- Use a strong model (GPT4 - not V!) and some careful, few-shot prompting templates to generate:
- a conversation between a questioner and an assistant, framed as though the assistant could see the image.
- What type of vehicle is featured in the image?
- What challenges do these people face?
- a detailed description of the image - using the label & bounding boxes to help GPT4 determine what is going on & generate a richer caption
- complex reasoning questions using the conversation & detailed description as inspiration
- a conversation between a questioner and an assistant, framed as though the assistant could see the image.
- Pre-training
- The CLIP-ViT is frozen, the projection matrix & LM weights are updated.
- Performed on 600K pairs from a captioned images dataset (CC3M) concerted to a “naive” instruction-tuning format of:
- <BOS> GPT4-QUESTION | IMAGE <STOP> Assistant: CAPTION <EOS>
- Fine-tuning
- 158K more complex, multi-turn instruction-following dialogues are used.
- Same free parameters as in pre-training.
- Evaluation:
- Following the Vicuna “LLM as a judge” methodology, GPT4 is used both to generate ground truth answers to novel instructions and as a judge.
- During their evaluations, LLaVA shown to significantly outperform BLIP-2 & OpenFlamingo at complex reasoning tasks and be slightly better at conversational tasks
- Failure modes: little semantic understanding of concepts within the images - e.g. photo of a fridge containing strawberries & yoghurt, answers "yes" to the question "is strawberry yoghurt present"
- So - instruction-tuning works really well and a clever process for synthetically generating the data helps get around the (relative) paucity of high quality multi-model instruction tuning datasets.
- Although the details of creating instruction-tuning datasets are glossed over in the more recent LLaVA series papers, the authors always mention that they are following the “LLaVA recipe”.
- The LLaVA Instruction tuning dataset is available on HF.
- The latest VLM model to follow the LLaVA recipe is the 72B LLaVA OneVision model (LLaVA-OneVision: Easy Visual Task Transfer) (ByteDance) which ranks creditably on the MMMU benchmark.
The LLaVA team observed that most generative VLMs can only respond to a relatively limited range of user instructions. They put this down to a lack of diverse, task-oriented data in the most important datasets (LAION, COCO, etc).
The MMMU Benchmark

- Massive Multi-discipline Multimodal Understanding (https://mmmu-benchmark.github.io/)
- Probably the most well-known and widely reported MM benchmark for VLMs
- Designed to measure three skills: perception, knowledge, and reasoning
- The questions were manually collected by a team of college students from various disciplines and subjects, drawing from online sources, textbooks, and lecture materials.
- Designed to require expert-level understanding from the domain in question in order to correctly answer the questions.
- 11.5K questions ranging over 30 subjects (e.g. history, clinical medicine, electronics, market research, music)
- Many problems will require expert-level reasoning to solve. e.g. knowing how to apply a Fourier transform to solve a problem.
- 95% of the questions are multiple choice (4 options).
- When first released in Nov 23, GPT4-V (top frontier model) scored 55.7% and LLaVA-1.5 (top O/S model) scored only 34%
- Now, o1 stands atop the leaderboard with a whopping score of 78.1% - 8% clear of InternVL-2.5, the runner up.
- Interestingly, GPT4 (text only) using the questions + captions extracted by OCR or LLaVA-1.5, scores 34% on the benchmark - highlighting the important role that reasoning plays in answering the questions
- Error analysis of GPT4V: Roughly evenly split between perceptual errors, reasoning errors and lack of knowledge.
- The Pro version of the benchmark involved removing questions which LLMs could answer, increasing the candidate answers from 4 to 10 and adding a “vision only” input mode
Multi-stage pre-training: the QWEN-VL series from Alibaba (2023/24)
- Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
- The QWEN series follows the self-attention architecture, using Qwen’s LMs as a backbone and a ViT vision encoder.
- A single, cross-attention layer (with learnable queries, similar to the PR) is used to resample the visual tokens, which are then injected, AR-fashion, into the decoder. This resolves the problem with AR architectures of large visual token-counts. Comparison with Flamingo’s PR:
- QWEN-VL uses 256 visual tokens, compared to Flamingo’s 64
- The single cross-attention layer means fewer trainable parameters in the QWEN-VL adaptor (80M) vs 200M in Flamingo - despite the 4x increase in token count
- 2D positional information is added to the visual tokens in QWEN-VL; Flamingo flattened the visual tokens
Training QWEN-VL
- The innovation here is to run a 3-stage training pipeline, adding an extra pre-training stage.
- Pre-training
- 1.4Bn (image, text) pairs from LAION, LAION-COCO, DataComp and Coyo, “filtered and cleaned”
- ViT and cross-attention layers are trained. LM is frozen.
- Images are resized to 224 x 224
- Multi-task pre-training
- To preserve LM performance, some of the pre-training data used for QWEN LM was mixed in.
- Added VQA datasets (GQA, VGQA, DocVQA)
- For grounding tasks, constructed a dataset from GRIT, RefCOCO and others, standardising the bounding boxes and references
- Added synthetic OCR data
- Images now sized at 448 x 448
- LM is unfrozen.
- We’ll see this theme again later on: to squeeze more juice from scarcer MM training data, pre-training on successively more complex tasks with introducing progressively richer input examples works really well.
- SFT
- A 350K instruction-tuning dataset is constructed via a combination of self-instruction and manual augmentation. (Details for the self-instruct process are not given)
QWEN2-VL
- The latest iteration of the QWEN series, QWEN2-72B, sits behind the leading models from OpenAI, Anthropic and Google on MMMU but above all others. The smaller models are open sourced but the 72B class is available via an API. The paper promises that the model will be O/S soon, but nothing yet…
Efficiently scaling VLMs: InternVL series from OpenGVLab (April 2024 onwards)
- Team is from the Shanghai AI Laboratory
- One of the challenges facing (particularly O/S researchers) building VLMs is the training cost.
- Even when using pre-trained ViTs and LMs, modality alignment pre-training is expensive - and, of course, grows with the parameter count.
InternVL
- InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
- Observation: Vision transformers are small and pre-trained separately from the LMs they will eventually be connected to in a VLM. Can we do better?
- They start with a 6B ViT architecture (for reference, a ViT-H/16 class would have around 600M and ViT-G/16 would have 1.8B)
- Training:
- Contrastive pre-training using the CLIP objective on 5B (image, text) pairs, using a frozen LLaMA-7B to embed the texts
- Initialise learnable queries and a cross-attention module to the LLaMA model and conduct vision-language generative training. ViT and LM params are kept frozen, the (image, text) dataset is further filtered for quality to 1Bn pairs and the BLIP-2 loss function is used: 3 components: image-text contrastive (ITC) loss, image-text matching (ITM) loss, and image-grounded text generation (ITG) loss.
- What we have now is a high quality, well-aligned ViT. The team demonstrate that SFT can be performed using a totally different LM, using the auto-regressive approach, and it works really well.
InternVL 1.5
- How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
- This was the question asked by the InternVM team: why do O/S VLMs lag frontier models? Their answer:
- Scale (obviously)
- Image resolution. Training using 224x224 or 448x448 resolutions means that details are lost, or that documents with a very different aspect ratio are horribly stretched or clipped
- They focused on improving the image encoder:
- They train a new 6B param ViT with a resolution of 448x448 pixels and adopt a “dynamic high-resolution strategy” that segments images into 448×448 tiles, with the number of tiles based on the aspect ratio and resolution of the images. (The tiling configuration is matched to the aspect ratio of the document.)
- a “thumbnail” of the entire original image is concatenated, providing a global view of the content
- a pixel shuffle strategy used to reduce the number of visual tokens by 3/4
- A similar strategy has been employed in QWEN2-VL, which no doubt contributes to its impressive benchmark performance
- Unfreezing the ViT parameters during VLM pre-training to enhances its visual representation capabilities, at the expense of higher training costs.
- They train a new 6B param ViT with a resolution of 448x448 pixels and adopt a “dynamic high-resolution strategy” that segments images into 448×448 tiles, with the number of tiles based on the aspect ratio and resolution of the images. (The tiling configuration is matched to the aspect ratio of the document.)
- Architectually, this is an auto-regressive architecture with a simple MLP to project the visual tokens to the LM.
- Results: competitive with the four, leading VLMs (Grok-1.5V, GPT-4V, Claude-3 Opus, Gemini Pro 1.5) on key eval benchmarks, including: MMMU, OCRBench (SoTA), DocVQA (documents)
InternVL 2 and 2.5
- The team introduce a trick for scaling up their VLMs to use larger LM backbones - up to a QWEN-VL 72B LM . Using a “progressive scaling strategy”, they align the ViT to a smaller backbone, then swap to progressively larger backbones. The claim is that vs. QWEN2-VL’s 1.4T tokens, they use only 120B
- InternVL2.5-78B is currently the top O/S model on the MMMU leaderboard, sitting only behind o1.
- Beats GPT-4o (0513), Claude 3.5 Sonnet (original), Gemini 1.5 Pro on MMMU, TextVQA and OCRBench
LLaMA3-V: large scale SoTA VLM using the cross-attention approach
- Just to prove that the cross-attention vs. self-attention debate is very much unsettled, the LLaMA3-V models have opted for the cross-attention approach.
- Uses the approach of a pre trained vision encoder - a ViT-H/14 - and cross-attention layers, trained on image/text pairs
- They note: As also demonstrated by prior work such as ViP-Llava (Cai et al., 2024), we observe that image encoders trained via a contrastive text alignment objective are unable to preserve fine-grained localization information.
- Recall that one of the reasons that the self-attention architecture seems to work is that, by using a CLIP or InternViT model which has been contrastively aligned with an LM, it’s a small step to re-map the embedded image tokens to another LM - hence a simple MLP connector will suffice.
- They introduce “temporal aggregator” layers and additional video cross-attention layers that operate on a large collection of video-text pairs to learn the model to recognize and process temporal information from videos.
- A fair amount of effort was spent on cleaning, safety-filtering, desensitising, deduplicating and quality-filtering on the MM dataset.
- Machine-generated OCR data is added to the pre-training mix
- They also do some synthetic augmentation of the pre-training images, at scale:
- visual grounding: adding annotated bounding boxes to the images to denote nouns and repeating the annotation symbols in the text around the relevant noun.
- Synthetic captions
- synthetically generated structured images - e.g. tables, latex
- the videos are likewise filtered for quality
- They insert 8 gated attention layers in between blocks of the ViT designed to learn “alignment specific features” prior to training the x-attn layers.
- Unlike other works, they DO NOT freeze the image encoder weights
- Existing LLaMA parameters were not touched during any stage of training, which helped preserve text-only performance.
- Cross-attention layers use Generalised Query Attention (GQA) for efficiency
- For video, temporal aggregation is done on every 32 frames (this is another perceiver-resampler, of course)
- SFT and reward-learning are both performed - the latter with a carefully managed DPO process
- LLaMA3.2 90B is currently the second-placed O/S model on MMMU.
Datasets
- Early VLMs were pre-trained using a large number of image/caption pairs crawled from the web. A popular choice has been LAION, with 5B pairs but newer datasets like DataComp (with 12B pairs) are larger.
LAION
- 5.85 Bn images with text captions extracted from the common crawl.
- Filtered using CLIP to ensure caption-image relevancy.
- The largest MM dataset that is publicly available.
COYO
- 750M image-text pairs, crawled from the web
- Higher CLIP quality threshold was applied than for LAION
- Added some further filtering criteria - an aesthetic score, probability of a watermark, etc
Interleaved Datasets
- Another strategy is to look beyond image/caption pairs and train on a large corpus of web documents. The idea is to download webpages, clean them to retain only the core content and then present it to the LMM - images and texts kept in the same order. This approach has been used by some recent and leading LMMs including MM1 and BLIP3.
- Recent research teams from Apple (MM1), Huggingface (IDEFICS) and SalesForce (BLIP) highlight the importance of interleaved image/text documents in the training mix.
- As we saw, during PT it’s normal to use the next-token prediction objective but simply to mask out the interleaved image tokens and compute the loss over the text tokens only
MINT-1T (2024)
- Multi-contributor team led by SalesForce
- A 1T token dataset including HTML, PDFs and arXiv papers.
OmniCorpus (2024)
- From the OpenGVLab (of InternVL fame)
- 2.2B documents sourced from Common Crawl dumps
- Contains 8B images and nearly 1.6T text tokens
Cross-Attention vs. Self-Attention
- Of the models we’ve discussed so far, only Flamingo and LLaMA3-V have used the cross-attention architecture whilst the rest are based on the auto-regressive architecture.
- On the whole, more teams have chosen to use use the auto-regressive approach.
Parameter efficiency
- The introduction of cross-attention blocks adds (according to Laurençon et al) roughly 25% to an LLM’s parameter count which need to be trained.
- The only new parameters required come from the projection component - which can be as as a linear projection (e.g. the original LLaVA), or a more sophisticated MLP. For self-attention, the count is more like 10%
Training efficiency
- In a cross-attention architecture, the LM “looks up” the information it needs from the embedded visual tokens.
- In the auto-regressive architecture, we have to unroll the visual tokens into the LM’s context window and apply attention across the entire sequence, resulting in lower training throughput.
Dynamic resolution and variable image tokens
- It’s easy to mix arbitrary numbers of visual tokens into self-attention models, because they are treated just like text tokens.
- In cross-attention models, we need to handle this with learnable queries which potentially compresses or shuffles around local features, affecting tasks like OCR or VQA.
The IDEFICS series from HuggingFace
- Laurençon, H., L. Tronchon, M. Cord, and V. Sanh (2024). [What matters when building vision-language models?](arXiv preprint arXiv:2405.02246) (IDEFICS 1)
- Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS**
- **Building and better understanding vision-language models: insights and future directions (IDEFICS 2)**
- The authors experimented with both architectures and evaluated the resulting models on a combination of VQA, OCR and captioning benchmarks.
- Key findings:
- When the LM backbones are frozen and only the newly initialised parameters are trained, the cross-attention architecture significantly outperforms the AR architecture. Perhaps not surprising, since there are more free parameters in the former.
- However, when allowing the LM backbone to be updated (using LoRA), the AR architecture performs much better.
- That said, training the LM without LoRA led to training instabilities.
- Improving either the LM or ViT backbone leads to a better VLM. The authors note that comparatively more attention has been focused on the former, rather than the latter.
- Adding a Perceiver-Resample to reduce the number of visual tokens both sped up training (for obvious reasons) but also improved performance.
- This result is at odds with findings by other researchers (e.g. Apple’s MM1 team) who report that more visual tokens and a higher resolution leads to better models.
- Cropping images into “tiles” (rather than processing them in natively higher resolution) seems to work very well as a simple strategy for processing image details. Adding this pre-processing step to the training data boosts performance on document QA and OCR tasks.
- For a fixed number of parameters, increasing the size of the LM backbone has a higher impact on the performance of the final VLM than the size of the vision backbone.
- The use of interleaved image/text documents (e.g. webpages with inline images) seems to be particularly important for few-shot learning.
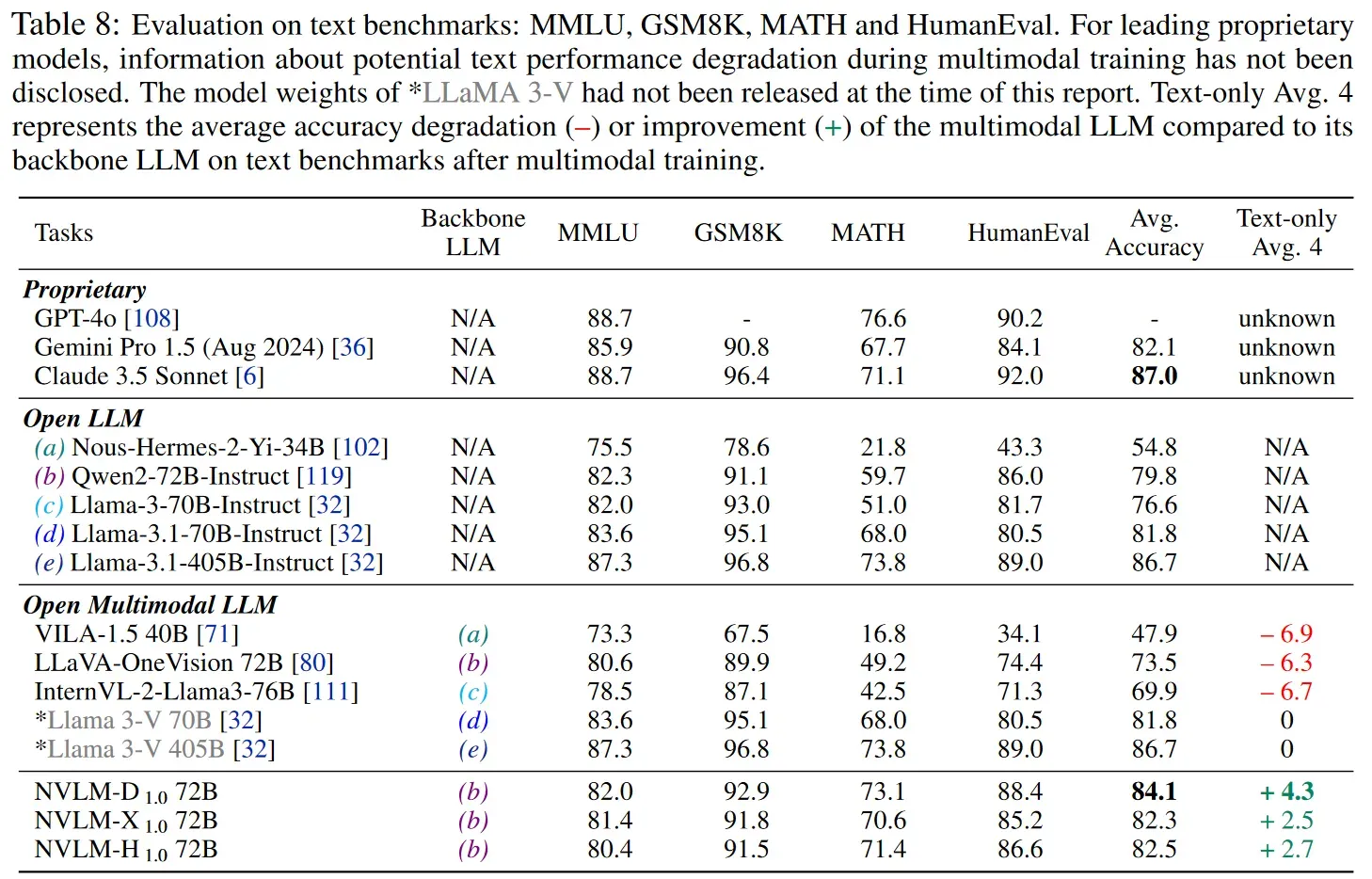
Comparing Architectures: NVLM (NVidia)
- Paper is: NVLM: Open Frontier-Class Multimodal LLMs (https://arxiv.org/pdf/2409.11402)
- They train 3 architectures, using a common LM backbone (Qwen2-72B-Instruct), Vision Encoder (InternViT-6B-448px-V1-5) and training mixture. These are:
- “D” - the decoder-only version
- “X” - the x-attn version
- “H” - the hybrid version
- Comparing X and D, they discovered that D has the best MMU, reasoning & OCR performance whilst X was more efficient to train
- They report that the Perceiver-Resampler seems to affect OCR performance in the cross-attention architecture - probably because it is shuffling spatial information which hurts fine-grained understanding tasks.
- Therefore, they propose “H” - a hybrid model where the image thumbnail tokens are mixed in to the decoder stream whilst the high-res patches are introduced via cross-attention
- This removed the need to unroll all of the high rest image tokens in the decoder, but still gives the self-attention mechanism direct access to the image.
- This sounds like a performance/quality trade-off - and indeed D beaths H on OCR tasks, chart understanding but H actually slightly beats X and D on the MMMU validation set, so I expect to see this hybrid model explored further in the future.
- They curated a high-quality, multi-source, text-only dataset and integrated it into the multimodal SFT stage. This preserved text-only performance - something which often degrades in VLMs.
- To this, they added a MM SFT dataset also comprised of a large number of benchmark and task-specific datasets.
- Interestingly, they saw improvements on LM performance on text-only math and coding benchmarks after multimodal training. They explained this by:
- the superb quality of the curated text-only data
- the significant amount of multimodal math data (e.g., geometry) incorporated into MM SFT blend, which improved NVLM’s reasoning capabilities, regardless of modality.
- Key finding from the NVLM paper: “dataset quality and task diversity are more important than scale, even during the pretraining phase, across all architectures”.
- This is echoed by the HuggingFace team, who spent extensive time curating new, diverse training datasets.
- However, “Models which use techniques to process images at high resolution significantly boost performance on OCR-related tasks but sometimes show reduced accuracy on reasoning-related tasks compared to their low-resolution counterparts.”
- NVLM is currently the third-placed open source model on the MMMU leaderboard, beaten only by the latest InterNVL2.5 model LLaMA3-V
Note the absence of a drop from LLaMA3-V due to it’s cross-attention architecture
Task-specific datasets
- Given the sophistication of interactions we’re looking for in our VLMs, we’d like even larger and more sophisticated task-specific datasets. Hence the work on synthetic data augmentation and complex task generation.
MS COCO (Common Objects in Context) (2014)
- COCO (Common Objects in Context)
- 200K images containing 1.5M objects from 80 categories
- Small, but high quality and important
- Contains High-quality annotations: Each image has detailed annotations including segmentation masks, bounding boxes and captions.
GrIT (2023)
- Not to be confused with GRIT - from AllenAI
- Constructed by a Microsoft research team as part of their Kosmos 2 grounded VLM
- 91M examples extracted from LAION and COCO
- use a pre-trained detector to extract noun chunks and associate them to image regions
- then, expand noun chunks to referring expressions
- noun phrases are explicitly associated with the bounding boxes, resulting in a high quality, grounding dataset
VQA
- Multiple questions per image, multiple answer options per image. Makes for 1M questions in the dataset overall!250K COCO images paired with open-ended questions about images - generated by MTurk workers. These questions require an understanding of vision, language and commonsense knowledge to answer.

DocVQA
- A set of 50K questions over 12K images extracted from a dataset of Industry documents.
- Contains PDF scans, charts and graphs, tables of data, invoices, hand-written notes and business info-graphics
- Task is to isolate and report precise spans of text to match a question: e.g. “What is the invoice number?”
The Cauldron
- 50 VLM fine-tuning datasets bundled up together. Probably the easiest way to acquire FT data now
- Mention this as a great way to find candidate augmentations and prompt structures
BLINK (Academic & AllenAI team, Jul 2024)
- Leaderboard here
- Paper here
- BLINK contains 3,807 multiple-choice questions ranging over 14 common perceptual tasks that humans can solve “in a blink” but which are difficult for VLMs.
- Human performance across the dataset is 95.7%
- Random guessing on BLINK would yield a score of 38.09%
- The authors contend that MMMU questions often reduce to a “dense captioning” task.
- What they mean is, if one replaces the image with a rich caption of the content, MMMU performance does not drop dramatically for a given VLM.
- The interpretation is that most of what MMMU is testing is reasoning and that less emphasis is placed on classic visual perception capabilities.
- Put another way, VLMs are great at learning generalised, compositional features from images which can be associated with language fragments but they lack many of the perceptual primitives that form the building blocks of human visual perception.
- Looking across the 14 categories on the leaderboard, there is a significant range between the best performing model within each category.
Best-solved BLINK tasks
- Art (GPT-4o: 82.91%; Human: 95.30%; Random: 50%). Given one reference painting image and two other paintings as options, the model is tasked with identifying the one that most closely shares the art style of the reference painting.

- Visual Similarity. (GPT4-Turbo: 80.74%; Human: 96.70%; Random: 50%). Given a reference image alongside two alternative images, the objective is to identify the image that most closely resembles the reference image in terms of visual similarity

- Forensic (GPT4o: 79.55%; Human: 100%; Random: 25%). Presented with a set of real and images generated by SDXL, the model must select the real one.

Worst-solved BLINK tasks
- IQ Test. (GPT4-Turbo: 32.67%; Human: 80%; Random: 25%) Given visual examples and a selection of images, the objective is to identify the image that either continues the pattern established by the examples or is spatially consistent with them
- Relative reflectance. (LLaVA-1.5: 39.55%; Human: 95.14%; Random: 33.33%). Compare the reflectance (albedo) of two pixels within an image.
- Functional Correspondance (GPT4o - 40.77%; Human: 80.77%; Random: 25%). The task presents an action alongside two object images. One image includes a reference point, while the other offers four potential points. The objective is to select the point that best matches the reference in terms of functional affordances.
- Interestingly, GPT4-o has improved in some tasks over Turbo and V but regressed in others:
- Significant Regressions: Counting(v: 60.83%; o: 49.17%; Jigsaw (v: 70.00%, o: 55.33%)
- Why? Hard to know, without understanding the architecture choices made in more recent GPT models, but this could be a result of:
- Distillation, with a focus on preserving reasoning and captioning tasks but less of an emphasis on basic visual perception tasks
- Specialist vision models still do better on most of the specific tasks in the BLINK dataset
Counting in BLINK, and related musings
- LLaVA-v1.6 34B leads with 66.67% vs a human score of 97.70% and a random choice baseline of 25%.
- Weirdly, the authors of Effectiveness assessment of recent large vision-language models (June 2024) find that 3 O/S VLMs (including LLaVA 1.5) outperform GPT-4V on counting tasks - getting ~30% each whilst GPT-V get's 0%
- In DeepMind's GeckoNum (Jun 2024) benchmark paper they observe that (img, text) training datasets do include numbers in the captions, but these are scarce. They argue that learning how to bind the numbers to the appropriate image features requires quite a sophisticated semantic understanding of the image.
- Anthropic provide a “best practices for vision” guide in which they demonstrate that good prompting techniques to decompose a counting task can improve accuracy. (Not the lack of sophisticated prompting in the BLINK evals)
- Directly annotating an image with a question (e.g. a maths question) is likely to render it similar to many images in the pre-training dataset. This can work better than providing the question in text along with an unannotated image.
- So we have a question:
- Are the BLINK team right: must deficiencies in working with perceptual primitives be fixed before VLMs can exhibit human-level performance in perceptual tasks; or
- Can strong reasoning compensate for such deficiencies?
- Probably, the reality is that:
- Perception is the primary bottleneck
- Strong reasoning can partially compensate for perceptual limitations
- The optimal solution likely requires improving both capabilities, with priority on perception
- Various commentators (e.g. HF) have suggested that the ViT architecture itself might require review - and/or the contrastive training objectives used.
Multimodal pre-training of a Vision Encoder: Apple’s AIMv2 (2024)
- Recently, the team at Apple reported a different approach to training a fresh vision encoder have taken a similar but different approach to took this by co-training a ViT and decoder with a recipe designed specifically to enhance the image embeddings.
- https://arxiv.org/abs/2411.14402
- Observation is that ViTs are trained using contrastive loss functions, whereas LLMs use generative pre-training - which is one of the secret sauces.
- Can we use generative training to pre-train the ViT?
- Consists of a ViT + transformer decoder setup - both trained from scratch
- Trained on a mix of 12Bn public & private (img, caption) pairs. Captioning a mix of alt-text and synthetic.
- Data is prepared with examples made from img patch tokens + txt tokens (in that order since this will result in a strong vision encoder)
- Training is done using prefix attention: a random prefix of visual tokens is unmasked, the rest of the visual tokens - plus the text tokens - must be decoded (with subsequent tokens causally masked). The decoder’s loss is only then calculated over non-prefix tokens.
- the entire set-up is trained with a next-token prediction task: MSE loss for vision tokens generated, standard cross-entropy loss for language tokens
- Recall that this recipe is designed to yield a strong vision encoder. So the decoder LM can be jettisoned when constructing a VLM. Indeed this is exactly what they did.
- To test the power of the new ViT in a MM architecture, they create a VLM by connecting it to LLaMA3 via a simple MLP and trained on the LLaVA SFT mixture.
- Comparing their new ViT with comparable contrastively trained, drop-in replacements, they see improvements in all benchmarks explored - but particularly significantly in captioning and VQA benchmarks
- I’d be very interested to see how switching the ViT from a leading O/S VLM for AIMv2 affects BLINK performance.
The next frontier: Multimodal Generation
- Understanding images is great; what about generating non-text data?
- The simplest way is to simply have your LM generate a prompt for an image and create that image with a diffusion model. This is what Gemini and GPT-4o are doing today.
- Image-generation supported by OpenAI (via DALL-E) and Gemini (via Imagen 3)
- The GPT-4o announcement demonstrated that the model could directly generate image outputs (”O” is for “Omni”) but this capability has not yet been released. So how might this be working?
Chameleon - FAIR (2024)
- Chameleon: Mixed-Modal Early-Fusion Foundation Models
- Predecessors:
- CM3: A Causal Masked Multimodal Model of the Internet
- CM3Leon (pronounced “Chameleon”)
- Everything discussed thus far has been “late fusion”. Separate modality encoders are used to encode images and text and then the models learn to align the embeddings.
- Is is possible to train a single encoder to work on both images and text?
- The first challenge comes in tokenizing the images. Up until now, we’ve used the term “image tokens” quite loosely - unlike text tokens (which can be decoded via a codebook back into text) the image tokens are continuous.
- The trick is to use a clever bit of machinary - the VQ-GAN. A simple overview:
- Encode and downsample an image, turning it into a set of latent vectors
- quantize the vectors using a learnable codebook of fixed size
- decode the vectors back into pixel-space
- apply a set of losses which consider different aspects of the reconstruction (including from the discriminator in the GAN setup)
- Now, the idea is to train a (LLaMA2) transformer decoder across mixed streams of input tokens.
- The team build a large pre-training dataset:
- Text only: 3T tokens from the LLaMA2 and CodeLLaMA pre-training datasets
- Text/Image: 1.4B open & licensed captioned images, cropped to 512x512
- Text/Image Interleaved: Following IDEFICS, 400B of interleaved image/text data scraped from the web
- The loss function is not explicitly described, but we can reasonably assume it is based on the CM3 (Causal Masked Multimodal Modeling) objective:
- The key to understanding the CM3 objective is to know that a simple, AR (next-token) loss function is insufficient for training over multimodal data.
- This is because, in order to train the model to learn cross-modal relationships, it’s helpful to be able to have some degree of bidirectional attention.
- For example, if there is an image in the middle of a text block, it’s going to be easier for the model to condition on all of the surrounding text when predicting the image tokens.
- The CM3 objective achieves this by introducing random masks to sub-sequences of the inputs.
- Masked regions are replaced with a special mask token and appended to the end of the sequence.
- We can now decode one token at a time, as usual. When we reach the masked subsequences at the end, the model can apply attention to all previous tokens.
- The Chameleon series is important in demonstrating a training recipe for early fusion VLMs which can generate images as well as consume them.
- The FAIR team note that training at higher parameter counts was tricky and they had to introduce a number of tweaks to the LLaMA2 architecture to stabilise it.
- What they demonstrate is that they beat LLaMA2 on most of the text-only benchmarks (again, this finding!)
- It is competitive with GPT-4V and Gemini Pro on captioning and VQA tasks
Transfusion (MetaAI)
- Previous approaches at MM-output generation:
- The Transfusion approach is to pretrain a transformer on 50% img & 50% txt using a next-token prediction & diffusion denoising objective, respectively.
- we don’t need to quantize the images in this architecture, so they are encoded using a VAE Encoder and then turned into “patches” (i.e. ”tokens”) via a UNET or simple MLP
- when decoding outputs can be handled in two ways, depending on whether they belong to a TXT or IMG region:
- TXT regions are handled with a simple linear layer to yield token probabilities
- IMG regions are processed by a UNET up layer & VAE Decoder, trained via a diffusion objective
- Causal attention for text, bidirectional for images
- This allows every image patch to attend to every other patch within the same image, but only attend to text or patches of other images that appeared previously in the sequence.
- Compared to Chameleon, this approach is more efficient - requiring only 1/3 as many flops to match the FID scores.
- INTERESTINGLY: it also matches Chameleon perplexity on text-2-text tasks at 1/2 the FLOPS…
- At 7B params, the model outperforms DALL-E2 and SDXL on the GenEval benchmark, whilst reaching LLaMA1 performance on text-only tasks
- For text, uses the Llama 2 tokenizer and corpus [Touvron et al., 2023b], containing 2T tokens across a diverse distribution of domains. For images, we use a collection of 380M licensed Shutterstock images and captions.
- Training on quantized image tokens degrades text performance more than diffusion on all three benchmarks.
- No instruction tuning was done so it’ll be interesting to see how well the transfusion recipe works for multimodal tasks
- Fine-tuned the 7B model using a dataset of only 8k publicly available image editing examples, where each example consists of an input image, an edit prompt, and an output image. Enables them to assess how well the model can generalize to image-to-image generation - which is not covered during pretraining.
- Team believes that that Transfusion models can adapt to and generalize across new modality combinations - but evidence for this was limited to small-scale, manual experiments.
Frontier Labs Offerings
- Image fine-tuning supported by:
- OpenAI for 4o, 4o-mini
- Google for Gemini 1.5 Pro and Flash
Frontier Class
| Developer | Model | Availability | Date | MMMU 0-shot CoT | BLINK | DocVQA |
|---|---|---|---|---|---|---|
| X.AI | Grok-2 Beta | Proprietary | 13/08/2024 | 66.1% | 93.6% | |
| Anthropic | Claude 3.5 Sonnet (New) | Proprietary | 22/10/2024 | 70.4% | 56.5% | |
| Gemini 1.5 Pro | Proprietary | 24/09/2024 | 65.9% | 61.0% | 93.1% | |
| OpenAI | GPT4-o1 Preview | Proprietary | 12/09/2024 | 78.2% | ||
| Meta | LLaMA 3.2 Vision (90B) | Proprietary | 30/09/2024 | 60.3% | 90.1% | |
| OpenAI | GPT-4o | Proprietary | 13/05/2024 | 69.1% | 63.2% or 68.0% | 92.8% |
| Alibaba | QWEN-VL2 72B | Open Source | 19/09/2024 | 64.5% | 96.5% | |
| OpenGVLab | InternVL2.5-78B | Open Source | 05/12/2024 | 70.1% | 63.8% | 95.1% |
| Llava Hugging Face team | LLaVA-OneVision-72B | Open Source | 06/08/2024 | 56.8% | 55.4% | 91.3% |
Mini Class
| Developer | Model | Date / Version | MMMU | BLINK | DocVQA | |
|---|---|---|---|---|---|---|
| X.AI | Grok-2-mini | Proprietary | 13/08/2024 | 63.2% | 93.2% | |
| Gemini 2.0 Flash (Experimental) | Proprietary | 11/12/2024 | 70.7% | |||
| OpenAI | GPT-4o-mini | Proprietary | 18/07/2024 | 59.4% | 51.9% | |
| OpenGVLab | InternVL2.5-8B | Open Source | 05/12/2024 | 56.0% | 54.8% | 95.1% |
| Microsoft | Phi-3.5-Vision- Instruct (4B) | Open Source | 17/08/2024 | 43.0% | 58.3% | |
| Gemini 1.5 Flash | Proprietary | 23/05/2024 | 56.1% | 45.8% | ||
| OpenAI | GPT-4o1-mini | Proprietary |
Why Does Phi-3.5V do so well on BLINK?
- Technical report doesn’t reveal anything novel in the architecture - it’s an AR set-up
- Nor does it give too many details about the datasets used, except:
- 0.5T pre-training tokens from a mixed dataset
- No vision-component to the loss during PT
- A very large SFT dataset - including a significant component built in-house - of 33B tokens
- A DPO step is explicitly mentioned
Concluding thoughts
- Is MM necessary for AGI?
- Top performers on MMMU are large and reasoning-heavy. 4o1-preview takes the top spot.
- However, given the correct training recipes, text-only performance is enhanced by MM pre-training.
- We see interesting regressions in reasoning-heavy models on BLINK, which suggests that we haven’t “solved” VLMs yet.
- I’d be very curious to see how Hybrid VLM architectures like NVLM perform on BLINK, given the duel-mode access to image features.
- Future of VLMs
- Expect to see a lot more on the true-MM models?
- Expect to see the scale of O/S VLMs increase further?
- Expect to see more innovation in the pre-training (or replacement) of ViTs. I have read comments about re-exploring CNNs - but maybe some other architecture is possible?
- Expect to see larger, heavily augmented datasets for SFT and second-stage PT, with new tasks being represented.
- Expect to see more exploration of alignment post-training also.
Full Transcript
Will Hardman: 0:00 Is multimodal understanding in an AI important on the path towards AGI? It's not entirely clear that it is, but some people argue that it is. So 1 reason that 1 might want to research these things is to see if by integrating the information from different modalities, you obtain another kind of transformational leap in the ability of a system to understand the world and to reason about it. I would say in inverted commas, similarly to the way we do. For open source researchers, like the last few months have really seen the arrival of these huge interleaved datasets, which has kind of really jumped the pretraining dataset size that's available. I'm kind of amazed that the Perceiver example works because it feels to me just like tipping the image into a blender, pressing on, and then somehow when it's finished training, the important features are retained and still there for you.
Nathan Labenz: 0:55 Hello. Happy New Year, and welcome back to the Cognitive Revolution. Today, I'm excited to share an in-depth technical survey covering just about everything you need to know about vision language models, and by extension, how multimodality in AI systems currently tends to work in general. My guest, Will Hardman, is founder of AI advisory firm Verity, and he's produced an exceptionally detailed overview of how VLMs have evolved. From early vision transformers to CLIP's pioneering alignment work to today's state of the art architectures like InternVL and LAMA3V. We'll examine key architectural decisions like the choice and trade offs between cross attention and self attention approaches, techniques for handling high resolution images and documents, and how evaluation frameworks like MMU and BLINK are revealing both the remarkable progress and the remaining limitations in these systems. Along the way, we dig deep into the technical innovations that have driven progress, from Flamingo's Perceiver Resampler, which reduces the number of visual tokens to a fixed dimensionality for efficient cross attention, to InternVL's Dynamic High Resolution strategy that segments images into 4 48 x 4 48 tiles while still maintaining global context. We also explore how different teams have approached instruction tuning from Lava's synthetic data generation to the multistage pre training approach pioneered by the Chinese research team behind QuenVL. Our hope is that this episode gives anyone who isn't already deep in the VLM literature a much better understanding of both how these models work and also how to apply them effectively in the context of application development. Will spent an estimated 40 hours preparing for this episode, and his detailed outline, which is available in the show notes, is probably the most comprehensive reference we've ever shared on this feed. While I have not worked personally with Will outside of the creation of this podcast, the technical depth and attention to detail that he demonstrated in what for him is an extracurricular project was truly outstanding. So if you're looking for AI advisory services and you want someone who truly understands the technology in-depth on its own terms, I would definitely encourage you to check out Will and the team at Veratai. Looking ahead, I would love to do more of these in-depth technical surveys, but I really need partners to make them great. There are so many crucial areas that deserve this kind of treatment and I just don't have time to go as far in-depth as I'd need to to do them on my own. A few topic areas that are of particular interest to me right now include first, recent advances in distributed training. These could democratize access to frontier model development, but also pose fundamental challenges to compute based governance schemes. Next, what should we make of the recent progress from the Chinese AI ecosystem? Are they catching up by training on Western model outputs, or are they developing truly novel capabilities of their own? There's not a strong consensus here, but there's arguably no question more important for US policymakers as we enter 2025. I'm also really interested in biological inspirations for neural network architectures or any comparative analysis of human and artificial neural network characteristics. The episode that we did with AE Studio stands out as 1 of my favorites of 2024, and I would love to have a more comprehensive understanding of what we collectively know about this space. I'm similarly interested in the state of the art when it comes to using language models as judge or otherwise evaluating model performance on tasks where there's no single right answer. This is a problem that we face daily at Weimarc and which seems likely to have important implications for how well reinforcement learning approaches will work and scale in hard to evaluate domains. Finally, for now, would love to catch up on the latest advances in vector databases and rag architectures. I've honestly been somewhat disillusioned with embedding based Rag strategies recently, and I've been recommending Flash Everything as the default relevance filtering strategy for a while now. But I do wonder, what might I be missing? In any case, the success of our previous survey style episodes, including our AI revolution in biology episodes with Emily Schreiber and our data data everywhere, enough for AGI episode with Nick Gannon, suggest that people find these detailed overviews to be a helpful way to catch up on important AI subfields. So if you have or are keen to develop deep expertise in an area that you think our audience would benefit from understanding better, please do reach out. I'm open minded about possible topics and very interested to hear what you might propose. You can contact us as always via our website, cognitiverevolution.ai, or by DMing me on your favorite social network. And of course, I'm more than happy to give you the chance to plug your product or services as part of your appearance on the show. Now I hope you enjoy my conversation with Will Hardman, AI advisor at Verity, about all aspects of vision language models. Will Hardman, AI advisor at Verity and AI scout on all things vision language models. Welcome to the Cognitive Revolution.
Will Hardman: 5:54 Thanks, Nathan. Great to be here.
Nathan Labenz: 5:57 Yeah. I'm excited about this. We've talked about this for a few months now, and you have put a real Herculean labor into a a very deep dive into all of the techniques, datasets, different strategies, variations on making vision language models work. I think this is gonna be a really interesting crash course and overview on all that. And, I think it's something that I know that I want and need, and I think a lot of people will, really benefit from getting the sort of fast forwarded version of all the research you've done. So thanks for, putting all the legwork in upfront to make this happen. And, basically, what I wanna do today is just kinda give you the floor, let you take us through everything that you have found to be important in vision language models. And I'll, you know, certainly, have my questions along the way as we go. But
Will Hardman: 6:49 Yeah. Please.
Nathan Labenz: 6:49 I'm excited for this.
Will Hardman: 6:51 Cool. Yeah. So this would have been obviously a lot easier to compile if the field had stayed still for 5 minutes, and the leaderboards hadn't jiggled around every day. And new papers hadn't come out every week, making me think, we should probably include this. But we're we're kind of at a checkpoint in time, so it's worth saying we're recording on 12/20/2024. We're still not the end of the OpenAI 12 days of Christmas, so something may change tomorrow. Paper may be released tomorrow, so this is kind of a point in time view of vision language models. And I guess it's it's a deep dive if, you know, if you're coming from the perspective of someone who's interested in AI, but not super familiar with vision language models. But if we're talking about vision language models specifically, it's definitely not a deep, deep dive into the research because it's huge. And there's so much going on and some of it's so complicated and so much we could cover. So what I thought we could do is just stick to like a few things. So firstly, let's look at some of the most important architectures and some of the trends in research. We'll illustrate these through some of the most notable models from the last couple of years. And these will be models that anyone who's working or building this space is quite likely to encounter. And then we'll talk a little bit, I mean, touch briefly on the key data sets and some of the benchmarks. And 1 benchmark in particular we'll explore in a bit more depth because it's really interesting. And then I guess we'll talk a bit about recent attempts at what we call true multimodality. So a vision language model is really reading kind of audio sorry, images and text inputs and then reasoning about them. But true multimodality would be generating images as well. And so we'll we'll kind of come onto that at the end. And then kind of we'll finish off, I think, just by taking a kind of as of today snapshot, what's best in class across some of the key benchmarks and where do I go and get it and what can I do with it?
Nathan Labenz: 8:45 That sounds good? Sounds good. Yeah. I'm already taking away that you're not classifying me as a truly multimodal entity in as much as I can't produce image outputs. So the talk about the bar rising quickly. I think I'm already outclassed by what you're calling the true multimodal models.
Will Hardman: 9:04 You mean you can't draw?
Nathan Labenz: 9:06 Not very well. Not not well enough that I would I would not see an API anytime soon. That's for sure.
Will Hardman: 9:11 Yeah. So in that case, I'm like you. I mean, I can just about doodle. That's about it. Because let's just to start off, like, all good research overviews with a motivation section. Like, why do we care? Because, obviously, there's lots of interesting use cases for VLMs. It was really interesting recently when you had the team from Google who were talking about the new Gemini APIs. 1 of the things they said was loads of people are building with large language models. Relatively few are building right now with visual language models. And that's, they think, gonna be a growth area next year. So that's that's kinda cool. There's there's loads of kinda use cases. The obvious ones like medical assistance, you know, being able to look at an image modalities as well as patient history and then say things about a patient that might be useful to the clinician. But I mean other use cases, content filtering, for example, and knowing what is in an image and text, for example, if you were looking on a social media platform and you're trying to screen out images or content of concern, indexing large quantities or archival material or product catalogs or something like that, where you've got both visual components and text components. You want to better understand, you know, what is this product given I can see it and given I've got some information about it. But I've also seen applications, for example, in insurance where people are having photos of cars, for example, there's a description of what's supposed to have happened to the car, there might be some damage, and the question is can I actually see the damage in the image? Does it kind of reflect what the person was saying on the report? Yes or no. There's various use cases. But I think beyond that, there's kind of 2 other reasons we might be interested in visual language models. 1 of them is that in building VLMs, you're learning to do is integrate 2 modalities. They start off very separates and somehow you're gonna reason over both of them. And then if you can find the recipes for doing this right, then into the future, you can think about, okay. Can I integrate audio, touch data, LiDAR data, other modalities? And if you think about, like, for example, robotics of the future, which you think about the number of kind of different sensory modalities you need to have a robot cook a meal, you know, it's got to handle everything, see everything. You can think about VLMs as being the first step to learning how to do this so we can integrate lots more for the future. So that's kind of a longer term thing. Secondly, and it's a bit more of a philosophical question is, is multimodal understanding in an AI important on the path towards AGI? It's not entirely clear that it is, but some people argue that it is. So 1 reason that 1 might want to research these things is to see if by integrating the information from different modalities, you obtain another kind of transformational leap in the ability of a system to understand the world and to reason about it. I would say in inverted commas, similarly to the way we do. We know they don't do things the same way we do. There you go. And I guess there's arguments against, know, is it important would be to say, well, look, frontier language models show lots of evidence of high level abstraction, world models, sophisticated reasoning. There's no obvious ceiling in performance as of today. Maybe a grounded multimodal understanding of the world is not that important for achieving AGI. But we'll kind of explore this. Maybe there are some little bits of evidence we'll come across today which might point us towards 1 or the other view here.
Nathan Labenz: 12:40 Yeah. I mean, I would be very surprised if we end up I mean, it just seems like imagine yourself unable to see. Right? It's like it would certainly be a major hurdle to have to get over. And my guess is that and maybe we'll, you know, shine some, light, so to speak, on this question as we go. But my guess is we'll never really answer that philosophical question of, like, could we have built an AGI that isn't multimodal? Because, you know, to state the most obvious spoiler in the history of the world, like, there has been a lot of progress, and it seems like if nothing else, it will be the path of least resistance. Like, multimodal is clearly going to work. The details are to be unpacked, but it seems like maybe, you know, the sort of philosophical crowd will continue to say, well, we might have been able to do it without multimodality or it would have been impossible. But, you know, it seems like in the end, this is going to be the norm and these things are gonna walk among us. Probably, if I had to guess, you know, sooner rather than later.
Will Hardman: 13:43 There's always sooner rather than later. There's no in this world. So I suppose before we dive into the first vision language model that we'll cover, there's probably 2 important little prefaces we ought to do. 1, we ought to talk about vision transformers for a moment. And then we ought to talk about the CLIP model from OpenAI. And the reason is that both of these are gonna crop up again and again. So let's just kind of refresh our memories as to what they are. And then we'll kind of dive into the VLMs themselves. So the vision transformer itself. So I'm going to assume we're all familiar with a language model transformer, especially decoder architecture. The canonical paper here is called An image is worth 16 by 16 words, which is from Google about 4 years ago now, 2020, I think. And previous to this, like most vision models have been based on convolutional neural networks. So they've basically been stacking convolutional filters to extract more and more global features from the images. And the question that the Google team asked was, Well, could we use the transformer recipe to build something that understands images? So the recipe is, let's say, quite straightforward. You take an image and you divide it into non overlapping patches, like this. Okay? You then linearize the patches and you have a linear embedding, which basically converts them all into tokens. Okay? So now we have just a sequence of visual tokens through a learned embedding. And then we feed these patches 1 x 1 into a transformer encoder, and we use full attention across it. So every little image patch can pay attention to every other image patch in the image. Okay? This is very similar kind of in thinking to to how a model like Bert is trained. Because what we do is they stick a classification token. They propend it to the sequence. And the training objective is, can you classify the image that you've seen into 1 of a large number of categories? You take the classification vector out the end, and that's what you used to figure out if you got the right classification. So very, very simple recipe going on there. And the key finding was that if you make these things big enough, these vision transformers, the transformer architecture does beat the convolutional neural networks of the day. And so that makes it a very kind of useful building block. There's just a couple of things we ought to take away from the design of the vision transformer, which is also called a ViT. So I'll probably use the word ViT throughout. The first is that note the image resolution is going to be fixed by design. So in the original vision transformer, was 2 24 pixels square. Okay. So everything has to be that size when we treat it in. Then we get fixed number of patches coming out. For the original training, they would stick, like I said, this classification token in. But when we come to talk about the vision language models later, normal practice is to take the entire sequence of hidden states from the transformer out and use that as your encoded image. So we don't just take the classification vector, we take everything. And that means you could get quite a lot of vision tokens out of such a model. So if you started with 2 24 times 2 24 is your image size and your patches were 16 times 16, bit of the back of the envelope math sells you, you're gonna get 196 visual tokens out of the end, which can be quite a lot. Okay? So that's the other thing to note. I guess the third thing is, and this is just a convenience, when we talk about vision transformers, you'll hear them describe like ViT H16, for example. And this just tells you something about the kind of dimensionality of the vision transformer. So the ViT is telling us a vision transformer. The h in that stands for huge. We just have to know that huge stands for about 600,000,000 parameters. And the 16 tells us the patch size. So that's what we're patching our images up into. So if I use that later on in here, you'll know what I mean. I say VITG 16, for example. It's a giant 1, which is even bigger than huge. There we go.
Nathan Labenz: 17:49 Hey. We'll continue our interview in a moment after a word from our sponsors. So couple little follow-up notes there just to make sure I understand this correctly. 1, just to contrast the image attention pattern versus the language model attention pattern, at least the 1 that we're most familiar with, which is like a look back only pattern, right, in language, the attention in the image context is generally all to all. Right? So there's no Cool. There's not, like, a sense of ordering or the sort of you know, obviously, language unfolds token by token. So that's 1 kind of fundamental difference. It's just that this is more of a which obviously reflects the modality itself. Right? The image is a snap of a a scene in time, and that is all on par with each other in the way that it's being processed all all to all. The other thing that I wanted to dig in on just a little bit more is how the tokenization happens. In language, we have these tokenizers, which sort of try to figure out, like, what's the sort of optimal way to and it's interesting that those are typically not part of the end to end training. Right? You sort of have this this this separate sort of bolted on system that, you know, people have try have kind of hated and have tried to get rid of for a long time, and maybe there's some signs that that could be about to happen. It's interesting. I was just reading last night a paper from Meta that's about a more dynamic, way to batch text as opposed to with these fixed tokens that are predefined. But
Will Hardman: 19:29 Sure. Yeah.
Nathan Labenz: 19:30 You know, if if anybody hasn't seen this, you can go to the OpenAI tokenizer and just paste in your text, and it will immediately chunk it into bits of text and color code them, and you can see what all the tokens are. So that's a vocabulary of Yep. Think now up to, like, a 100,000 different little bits of text that text is broken down into before it is translated into numeric form and then processed. And that translation of this token to this vector representation is something that at runtime is fixed, and there's basically as many Yep. People often refer to this as 1 hot encoding where there's as many possible input vectors as there are tokens. Yeah. How that that's a bit different now in this case, right, for images. My understanding, if I'm understanding correctly, is there's not, like, a fixed vocabulary size of
Will Hardman: 20:29 That's
Nathan Labenz: 20:29 of possible tokens. Right?
Will Hardman: 20:30 That's correct. So we're gonna use the term throughout most of it. We're gonna use the term tokens quite loosely because as he correctly says, you know, tokens can be mapped back to text through a code book. Literally got, you know, 80,000 codes. You look it up and you get your byte pair or whatever it is at the end. The same is not the case with visual tokens. They exist on a continuum, as you pointed out. So to go from your little patch, which is really just a matrix, you've got some few dimensions and channels in there. You're simply going to pass that through a matrix, which is going to generate you the vector that you want to stick in to the transformer. And it's learnable. That transformation is learnable. But the important thing is that your tokens are going to come out on a continuum. Okay. And they don't need to be quantized at this point. There's nothing in the transformer architecture that says tokens have to be quantized to a code book. You can still run the attention mechanism even if your tokens exist on a continuum like this. Okay. Cool. Note that because we're training, like you said, the visual, the vision transformer with a classification objective, we don't actually have to decode anything at the end. So it doesn't matter.
Nathan Labenz: 21:43 I'll then I'll save my next question I have for as we get a little deeper into the journey here. I think the last thing that's worth just reflecting on for a second is just how small the images are that are being processed. So I've done a little bit of this, not recently because these days we have these foundation models where I can just throw basically anything into it. I think
Will Hardman: 22:03 Yep.
Nathan Labenz: 22:03 There are some hard limits that I've run into occasionally if my image is, like, north of 10 megabytes or whatever. But typically, just throw it in there. They handle it. You as a developer don't really have to worry about it. With earlier generations of models, you did have to do this sort of preprocessing where you would take your image. It was your responsibility as a user of the model that somebody open sourced for your, yeah, convenience to take your image and basically morph it or, you know, I guess resize it is probably the the right term into the required size that the model could handle. And it's, you know, presumably just because everything was smaller back then and, you know, compute resources were more limited and the results weren't so spectacular in general. Mhmm. 2 24 x 2 24 even until fairly recently. And even with, like, the OpenAI kind of small mode, whatever their sort of low res mode is, it is remarkable how much performance can come out of these, like, very small images even when they're dramatically shrunk and they're often, like, significantly distorted because your original image might not have even been a square, but you're just kinda like, whatever. I'm just gonna make it a square. I don't care if things are smooshed. I don't care whatever happens. That's what we're gonna work with. And it's amazing to me how well that actually works. And and I think these days that's getting liberalized for sure because it's not all low res on, like, the OpenAI API, but it is remarkable how far that can go.
Will Hardman: 23:33 Yeah. Without wanting to spoil the big reveal, of course, they're not compressing everything to 2 2 4 x 2 2 4 and using that as the image inputs. There's a much more sophisticated and smarter things going on, at least with the the leading visual language models. So we'll see how they do it in a bit.
Nathan Labenz: 23:51 Okay. Cool. Well, let's carry on. That's a great start.
Will Hardman: 23:54 Cool. So that was the vision transformer. And I think the other thing is that we should introduce right now is the CLIP model from OpenAI, because that's again gonna be really fundamental. And the paper here is from back in 2021, and they called it learning transferable visual models for natural language supervision. And CLIP itself stands for Contrastive Language Image Free Training. So it's a canonical model in the field, and it's a really nice introductory 1 to study for how we align image and text encodings. Okay? So the idea is you start with a vision encoder, which could be a vision transformer, and a text encoder, which could be an encoder only transformer. And you've got a large dataset of images with their captions that have been scraped from the web. Okay? So the process is to jointly train both encoders so that they're generating embedding vectors, for the text and for the images, such that if you take an image in its caption, the 2 vectors are going to have very high cosine similarity for an image in its caption. But if I take 2 random captions of the image, they will have low similarity. And the way this is done is you simply pass the image through the vision transformer, the text through the text transformer. You then add just a linear projection to get them kind of the same conforming dimensionality. And then use this contrastive loss function. And then what that does is says, suppose I've got a batch with like N image caption pairs in it. I know within that, that I've got N true pairs and I've got N squared minus N bad pairs. Okay? So you set the loss function up to say penalize any dissimilarity between my true pairs and likewise penalize any similarity between the non pairs within the batch. And that's a contrastive loss function. It's basically bringing things that are supposed to be the same close together and pushing the vector representations apart for things which are not the same. So that was how the CLIP model worked. And 1 nice thing about this is that once you've trained it, I mean, obviously you can use CLIP itself for things like image search, but you can also just take the trained vision transformer out of it and use it downstream. And that's really nice because what you've done is you've already, in some senses, kind of trained it to embed things similarly to a language model. So therefore, we were going to put that into a vision language model, it should only be a small step away from being aligned to whatever we're to use in that model. So there's the thinking there. And that is why, as we kind of go through to the rest of today, we're going to see that they very often, the researchers start with a CLIP. Gets them kind of 2 thirds of the way there. So I wasn't going to do a deep dive into the CLIP model, but just to say that, you know, it is a vision transformer. That's how it's trained using this contrastive loss objective, and we can now use it downstream.
Nathan Labenz: 27:02 Yeah. I remember using this 1 in the early days of way mark small business video creation. We were at the point where we could get the fine tuned GPT-three to write a somewhat decent script. You know, certainly things have improved a lot since then. But then you had the challenge of, okay, now that we have this narrative that we wanna put together for this random small business, and we've also found all these images off the web. Mhmm. What should we choose out of this bag of images? Right? And at the time, you know, you had sort of prior to CLIP, you had, like, classic know, most of this stuff was done on finite sort of pre established datasets. Right? I mean, 1 of the big advances of CLIP was that they moved from your, like, image net type thing where you have a certain canonical set of images with a certain fixed set of classifications. And the the game used to be about how you know, comparing architectures basically. Right? Can I come up with an architecture that on this standard dataset does a better job than everybody who came before me in some way, shape, form there Yeah? Yeah. Where I can claim to have state of the art, and I'm great. That didn't do much at all for us with a application like Waymark because it was you know, maybe could have made it work, but it would have been very noisy because it it would have been like, well, the image that I have of this, you know, business, whatever it may be, potentially is not even well represented at all by any of the classes in an ImageNet set of classes. I think it's 1000 classes that they have in ImageNet, and there were smaller ones before that that had fewer classes. So this was the first moment, as far as I know, where they went let's forget competing on these standard datasets. What people really want is to understand anything that they might be looking at, and the web scale data is out there, and enough of these images are captioned. And by the way, when you really got into CLIP, tons of noise in the caption data. You know, typically, if you just ask yourself, like, how do people caption images? You know, it's lots of different ways. You know, sometimes with jokes, sometimes with just a straightforward description of what's in it, sometimes with line from a poem. You know? I mean, it's a so tremendous amount of noise in that original dataset. We found in using it that it was pretty good if you said, okay. I I want an image of this. Which of the images from this set of possible images most closely matches that query? We could get a pretty effective sort, but we'd see all sorts of artifacts and weirdnesses. Like, sometimes if the text that we were you know, let's say we were, for example, doing a video for a pizza restaurant. There's a pizza restaurant in Detroit that I've always kind of used as 1 of my go tos. If you put the word pizza in as your text query and run that through the text side and then put all the images through the vision side and, you know, each 1 now is represented by the vector. And as you said, like, if they're similar, you should have a high cosign similarity. So, basically, literally multiply these vectors together, take the sum, and sort by that. That was the the procedure. But sometimes what you would find is if the word pizza in text was in the image, then that would, you know, pop to the top. And so you'd have all these sort of weird things to deal with. I think largely as a reflection of the fact that this was just extremely noisy web scale data that at the time, they didn't really even necessarily have a great way to clean. Right? Because it's like all this technology is kind of being created out of nothing. You know? These days, you would say, well, why don't you filter those? You know, images that have, caption image content mismatch or that seem nonsensical. And I think the answer at the time was basically, we have no way to do that. So Yeah. Just had to try to throw as much data into this as we can and hope that some signal comes out, and it did. We did find also that, I promise I won't do this every single step, but I have memories of CLIP. Aesthetics were basically totally unrepresented. And I I guess this would be because a few of the image captions found online are like a beautiful picture of x or, you know, an unattractive picture of x. But we wanted that because small businesses have very wide ranging quality of pictures. Sometimes you get user generated content stuff posted on their Facebook. Sometimes it's professional. The difference matters a ton. Right? They do not want some of these ugly images that might be associated with them online in their marketing, but how could you tell? There was no real aesthetic signal in CLIP. It was all content, but not quality. So Yeah. That's crazy. That wasn't all that long ago. No.
Will Hardman: 32:02 We're we're still 3 years, 4 years ago, And and now now we're gonna jump to 2 years ago. And then everything else we talk about is gonna be in the last 2 years. And you're right. 1 of the stories that's gonna unfold is we kind of cover a few of the VLMs today is this increasing obsession with filtering data for quality. So both the pre training and for subsequent by streaming stages. And that is to kind of get rid of this problem of noisy data, which really does seem to hurt VLMs in particular.
Nathan Labenz: 32:31 Cool. Well, I think that's enough memory lane down the cliff alley for me, so let's keep going. Hey. We'll continue our interview in a moment after a word from our sponsors.
Will Hardman: 32:43 Okay. So we're gonna jump forwards then to 2022. And a model that I've heard described as the GPT-three moment for vision language models, and that is DeepMind's Flamingo model. A number of really interesting innovations in this. And so it's worth covering this in a bit more depth. Also it's the first example we'll see of actually how a VLM is constructed. Okay? So the basic pattern, and I'm going to see this through all of the models we cover, is that you're going to encode the 2 modalities, that is text and images separately. So you can use a text tokenizer, and you're going to use an image encoder, normally a vision transformer. We're then going to select a language model, which is called the backbone. And the backbone is going to be the thing that does all the reasoning of both the text and the images. And that just leaves us with a question of how we connect the 2. So for example, in the Flamego model from DeepMind, they chose they actually looked at a vision transformer and a convolutional neural network. Everything I've looked at since has been just using a vision transformer. And then they used a chinchilla language model. Okay. So to connect the 2 things together, they decided to freeze the language model and then introduce cross attention layers sandwiched between, I think every fourth transformer block in the chinchilla language model. Okay. So the idea of the cross attention layers is that they're going to look up information that we got from the vision transformer. And there's immediately, on thinking about it, you might see a couple of challenges that need to be resolved for this to work. So the first is if we've got an input, say, that's got more than 1 image in it, then obviously when we've encoded those, we're going have a variable number of image tokens generated. And if we're using a cross attention mechanism, so it's similar to self attention, other than the keys and the values are not coming from the text we're decoding, they've got to come from the image, then that's a problem. Because obviously the dimensionality of the cross encoder mechanism is fixed. So we need a fixed number of visual tokens generated. So what if we got 2, 3, 4 images, all which were different sizes of images? And then second question is we can sometimes get a lot of visual tokens. So if we want to train really efficiently, is there a way to like reduce the number of visual tokens that we're actually going to attend to? That would just make trailing the model a lot easier. Okay. Cross attention layers don't need to be quite too deep. So the way that the DeepMind team solved this is, I think, very smart. And they used something called a Perceiver resampler, which might actually been their innovation, I think. So Perceva Resampler is like a separate model that's going to be introduced. So not all cross attention layers. We're introducing a separate fresh model here. It's going to look at the visual tokens and it's designed to select out or sample, resample the most important visual information that the vision transformer has encoded. But you want to do this in such a way that if you have a very, very, very long sequence of vision tokens that have come from 1 or more images, what you don't want to do within your perceiver resampler, which has its own attention mechanism, what you don't want to do is compute the kind of all to all sequence times sequence attention matrix, because that could be very big. Okay. So the innovation here is that in a normal attention mechanism, you've got your queries, keys and values, right? And they all come from the context that you're decoding. All right? So the idea here is that explosion comes from the fact that the queries need to be multiplied by the keys at some point. That creates this all to all attention matrix, which is size of the sequence length squared. And it is, of course, the bane of transformers. So what they did in the perceiver model is they said, well, what if we jettison this need to come up with queries based on context that we just ran? What if we instead have, like, a small number of fixed queries? And when I say fixed, mean learnable. So they're just latent factors that can be learned at training time. And they selected for Famengo, they selected this to be 64. 64 query vectors, which can be learned at training time. So in the Perceiver Resampler model, you're going to look at all of the visual tokens that have come in. Your query is going to be a size 64. So the actual query key matrix that you calculate is now sequence length times 64, which is way, way, way smaller. Okay? The beauty of that is once you finish the attention calculation in the posterior resampler, you've got something that's 64 times whatever your hidden dimension is. So it could be 7 68, for example. So again, you get something very small out of it. And the Perceiver Resampler Model is a module that's essentially this, and it does it in a number of stages, but it's essentially just using these learnable keys. And the nice thing is about the end, we know the size that the visual tokens are going to be at the end, 64, 77, 68, for example. Which means that we can now define a cross attention layer, which is always gonna read visual tokens of that size that have come out of the vision transformer. Is that making sense?
Nathan Labenz: 38:02 Yeah. And this happens after the initial vision transformer layers. Right? So Yeah. We've got still the all to all attention happening on the vision side of the it's kind of too I can remember the chinchilla diagram and even more so I can remember the, bowl of yarn soup that I went around showing to people at parties in 2022 and into summer when I I was like, look at this. This exists now. So you've got basically again, very similar to to CLIP, and and this will be a pretty common theme, although there are some exceptions too. But images being processed through 1 kind of main model, text being processed through another main model. These things are often totally frozen at the time that we now wanna figure out a way to fuse them. And the way to fuse them is 2 parts here. 1 is across attention, but then the second is figuring out how to essentially make life easier for the cross attention and the the kind of main language model that's gonna carry things on by finding a way to standardize the sequence length for the image. So toward the end of the image processing with its full attention, then there's this sort of adapter that Yeah. Says, okay. Regardless of how big the image was or how many tokens, whatever, it's always gonna be output from this step at 64 tokens. And therefore, the cross attention can always be the same size, and everything downstream of that can get simpler. I think this is a really interesting thing. I mean, I I probably didn't have the sophistication at the time to appreciate it, but it's a good indicator of just how malleable all of these latent spaces are and how sometimes say, like, everything is isomorphic to everything else, which I think probably doesn't actually mean anything. But it's, you know, the intuition that I'm trying to express there is just like, I've seen so many of these things at this point where 1 space is bridged over to another space or, you know, reformed or, you know, you almost see this even just with the libraries that are used. Well, I'm thinking of all the Python libraries that allow you to, like, reshape matrices. Yeah. It's almost like, you know, those matrix reshapings are you know, you don't think of those as, like, semantic, but when you scale them up to this sort of thing, a very similar thing starts to happen where you're like, okay. I've got all these, you know, all the all, but what I really need is just a sequence and it needs to be fixed length. And, okay, I'm just gonna train a thing that no matter what, it's gonna output a fixed length sequence and hope it works. And, I mean, not everything works. I'm told by the researchers, you know, there are many failures along the way, but it sure seems like almost everything of this sort kind of works. And I think that's a really striking reality. I remember seeing this 1, and there were there was blimp 2, which was another 1 that really brought it home for me just because of how few new parameters had to be trained. I don't know if you have those numbers, like, right off, the top here, but it's a strong contrast between the amount of parameters and pre training on both the text and image side versus how small these connectors can be in many cases.
Will Hardman: 41:36 Yeah. So 1 of the teams from Hugging Face did a comparison, and we'll talk about it in a bit more detail later. They said in a 7,000,000,000 parameter language model class, if you add the cross attention layers in, that's about 25% of the parameters now need training. Whereas I said, if you're gonna do it the other way, which is just a simple projection, that's about 10%. So you do introduce a lot more parameters using this kind of cross attention mechanism that we're talking about, but it's still, it's small compared to retraining the whole language model. And that's actually 1 of its benefits is that you can literally freeze the vision transformer if you want. You can freeze the language model and just train the cross attention parameters and the Perceiver Resampler. And like you, I'm kind of amazed that the Perceiver Resampler works because it feels to me just like tipping the image into a blender, pressing on, and then somehow when it's finished training, the important features are retained and still there for you. It feels to me like they would have all been mixed up. But I guess it goes to show intuition, at least for me, doesn't really work when it comes to these like very sophisticated mechanisms.
Nathan Labenz: 42:45 Yeah. Okay.
Will Hardman: 42:48 Cool. So let's just say a little bit more then about So we've got the Perceiver Resampler. We've got the language model. And then to train them, you simply need to switch on your next token prediction training objective and start training the new nilishinized layers in the language model. And that's not too difficult to do. And what's happening is you're replacing where your images would have been in the text prompts that you're giving to the language model during this training. That's prompting it to look up the outputs from the perceived resampler. So these are not tokens that get scored, for example, when you're decoding, but it's prompting it saying, when I see this token, it's okay. I need to go and look up something in the perceived resampler, and that's gonna give me enough context to know what the next token should be, because it's where the image would have been my input text. And in terms of the training datasets, like to see how this actually works in practice, they obviously used images paired with their alt texts, which is the same that's used in CLIP, but that's not enough. And 1 of the contributions that the Flamingo team made was to realize the real importance of what's called interleaved data. So interleaved data is basically data scraped from the web, like HTML documents, where you've got images and you've text in the document. And they know by looking at the document object model when they scrape the website, they know kind of roughly what order these things are supposed to appear in. That interleaved data sets that you can then pass through your decoder, and then you can say, you know, when you get to an image, look up the image, you know, now I'm going to keep on producing the text. They found that it was really, really important for actually maintaining all of the kind of downstream performance metrics. So interleaved data turns out to be super, super important for vision language models. That was 1 of the kind of major findings of the Flamingo paper. So in terms of how they evaluated this thing, once they'd done the training, it was visual question answering and OCR and captioning. Those are kind of the key tasks they looked at. And they discovered, firstly, it works quite well in a few shot setting. So the training was very compute efficient because you don't need to touch anything in the language model under the newly initialized parameters. And yet the output was still very competitive with very much more focused task specific models. So they had a model that could do several things and it could be competitive with all the task specific ones. And that's why it was a really kind of, I think foundational model in visual vision language models. It's because you have this kind of several tasks you could perform and you have this 1 training recipe strongly based on the transformer training recipe. And the basic pattern of using cross attention layers has been used by other teams since, but it's not the only way of doing it. And we'll come on to the other way in just a second.
Nathan Labenz: 45:38 They never released flamingo to the public, did they? I don't remember ever having a chance to actually use it. Just remember I
Will Hardman: 45:48 don't think they did, unlike what we'll come on to in a second and and most of what we'll cover today.
Nathan Labenz: 45:55 Yeah. That was before Google was dancing, I guess.
Will Hardman: 45:59 Mhmm. So that's the basic training recipe we just covered for a cross attention model. 1 of the things that makes large language models so good at what they do is the instruction tuning. And that's proved to be 1 of the big unlocks. And in the Flamingo recipe there, it's not kind of clear, you know, there was no specific instruction tuning step. And the difficulty there was, it's definitely difficult to come up with an instruction tuning data set, right? There weren't such things around, there are now. And that kind of this, how to do this is the contribution of the next model that we're going look at, which is the NAVA model, which stands for the large language and vision assistant. And this is a 2023 vintage model. We've already jumped on like another year. So the original lava model comes from a mixed team, from some people from Microsoft and then from academic institutions. And it's the first in kind of a long series of lava models, all of which are kind of been based on the same recipe. The big innovation here is instruction sharing and how they built the instruction sharing dataset. They start with a key observation that the generative vision language models that existed at the time they built this could only follow a relatively limited range of user instructions. So they could do some captioning for you. They can answer some basic questions about images, But they couldn't do anything like the range of tasks that a language model could do once it had been instruction tuned. And 1 of the reasons they put this down to was just looking at the big datasets that we used training models. You have the interleaved text and images from crawled web documents, and you also had these big captioning data sets. We'll talk about a couple of them in a second. But relatively few of them were actually containing lots of task oriented labels for the images, and that was just missing. So the question is how can you build such a thing that would work for a vision language model? And you should probably talk a little bit about the basic architecture of Lava, because it actually looks different to the Flamingo model. We talked about the Flamingo as described as being a cross encoder model because they've introduced these new cross encoder layers. The Lava team chose actually a simpler approach, and this is pioneered, I think, by the Salesforce team that built BLIT. So we can call this the autoregressive architecture rather than the cross attention architecture. And the idea is that you're gonna take your vision tokens, which have been processed by a vision transformer, Even better if it's from a CLIP vision transformer, because that's already been aligned in the past to a language model. And then gonna train a simple projection matrix and inject the tokens directly into the decoder stream. Okay. So no cross attention needed here. You have a simple projection matrix and then you're going to mix them in. But then in the original lava architecture, they kind of prepended all of the text tokens that were going into the language model backbone with all of the vision tokens. So your kind of training sequences will be bunch of vision tokens, text, and you'd then be attending to everything to the left. Okay. So that's the autoregressive architecture. Seems a lot simpler than the cross attention 1, but it's got maybe 1 or 2 downsides to it. The first is that if we generate a long sequence of vision tokens from the vision transformer, we've literally now got to unroll all of them in the decoder. Right? So they're all going to be part of the attention mechanism in the decoder. Right? So that's kind of 1 disadvantage perhaps. The second is that if we've got this projection matrix as was used in, and I think they used a simple, like a linear layer in the LASA model, that gives you many fewer parameters in introducing a big cross attention mechanism. So you've now got to learn all the alignment using those parameters. And if you want to do anything further, if that's not enough for you, you've got to untreeze the language model backbone, and you've to start mucking around with the attention mechanism. So 1 of the downsides there, as we know, is we start fine tuning the language model and the attention mechanism, it's very easy to kind of suffer catastrophic forgetting on some of the tasks that the language model was fine tuned for in the first place. This there's 1 of the downsides of using this ultra regressive architecture that just uses self attention. But that's what they chose to do with Lava.
Nathan Labenz: 50:34 Yeah. You mentioned BLIP. We did it. 1 of my first episodes actually of the podcast was with with the authors of BLIP 2. And I remember this sort of, you know, moment of understanding where I was like, wow. So they are somehow converting these images into text embedding space and treating the images as if they were text from that point on. The rest of the model doesn't even know that it has been fed anything other than text because, you know, it's it's frozen. Right? So, I mean, it's been trained to handle text. It can only handle text, but now somebody's figured out how to represent these images as text in the text embedding space. And 1 of the really interesting things about that was how you are accessing parts of text embedding space that text itself can never get to. Right? It's similar a little bit to what we talked about earlier where the you have the 1 hot token level text encoding, but these image projections into text embedding space are not bound by that. At least they weren't in the BLIP 1. I don't think they would have been in this lava 1 either. And so you're just accessing you realize that, like, the space of possible inputs is actually hugely bigger than the space that the actual 100,000 token vocabulary routinely accesses. And that, again, just kind of magically seems to work. It's like 1 of these, you know, divine benevolence things where you're telling me we trained an entire language model on nothing but this 100,000 tokens. And now it's gonna be just we're gonna bypass, you know, that layer and just directly go into embedding space with whatever is learned by this projection process, and the language model is still gonna handle that normally? And the answer is yes. It's Yeah. Kind of amazing.
Will Hardman: 52:47 It's quite an amazing result. I mean, as a simple projection matrix, taking takes your vision tokens, lets you mix them in. I mean, and in other models, arbitrarily mix them in with the text tokens, and it doesn't destroy the performance of the transformer. It doesn't seem to need complete retraining of the attention mechanism. Like that simple projection matrix is enough to get it to work with the visual tokens, which I think is quite an amazing finding.
Nathan Labenz: 53:17 Yeah. No doubt. I mean, I don't like to do analogies all that much, but I'm just I'm trying to sort of imagine, like, what is there any, you know, sort of analogous challenge that we could post to a human? I mean, we're obviously natively multimodal, but to to think about putting something into word space that is not words, it's like kind of going directly into thought space, I guess. And, yeah, that was there were a few of these moments. For me, I think 1 of the reasons that I got so obsessed as early as I did, not having had, like, a, you know, an academic background in the subject was seeing how the architecture was working across modalities and then starting to see these bridges where it was like, boy, if you can just take 2 frozen things and kinda mash them up in a couple different ways and they all kinda seem to work, then that means we are headed for a world where all of this is gonna be integrated, and it's going to be quite something to see when that happens. So I these were, for me, like, very leading indicator moments of just how much was almost certainly gonna be possible. It was like if if the language model could do that and not break, then I think, you know, we've got to expect that there's gonna be just a lot more Frankensteining to come, much of which, you know, might be weird in all kinds of ways, but a lot of it's gonna end up being viable.
Will Hardman: 54:46 Yeah. Absolutely. So we said we'd talk a little bit about how they did the instruction tuning with the lava model. And as this is, I guess, what the main contribution of the paper was. We've talked about what the autoregressive architecture looks like. So the way they did this is actually really, really smart. So they started with images from a dataset called COCO, which was produced by Microsoft, I believe, back in 2014. And the idea behind that, there's about 200,000 images in the COCO dataset. You've got images, and then you've got descriptions with bounding boxes in them describing what's in different areas in the image. And so that actually appears in the text, you know, says in this area, region, and then this thing, region is this thing. And the idea is that it's to teach visual grounding for vision models. So what the lava team did, which is very smart, is they used a strong model. I think they used GPT-four, not a vision model, just a language model. And a very careful and clever set of few shot prompting templates. And they asked the GPT-four, can you generate a conversation between a questioner and a vision assistant framed as though the assistant can see the image, although GPT-4 cannot see the image. Okay. So for example, given the description of an image, might say, here's a bunch of people standing around the vehicle, there's luggage on the floor, and then some bounding boxes. Here's a piece of luggage. Here's a bicycle sitting at the side. Here's a person. And so in the bounding boxes. So read that GPT-four and now come up with a question for me. Okay? As though you could see the image. So the question might be, what type of vehicle is in the image? Okay? And that's not easy for a GPT-four to do because it the image the caption will say what kind of vehicle it's in. But then you can think of more intelligent questions. For example, what is the thing to the left of the car? And we know from the bounding box that there's a thing, you know, the thing to the left of the car is a bicycle. Right? So not even needing to see the image, you can come up with that question just by simply computing the bounding, where the bounding box is. Or you could ask a more in-depth reasoning question like what challenges do the people around the car face? So people are loading luggage into the car. Alright? So if you just saw the image, you would have to infer all of this stuff from the image. So the really smart thing here is getting these kind of conversational dialogues built up by a strong model like GPT-four. And then you've actually got all of this data you can use for instruction tuning. So you're gonna ask the questions and you've also got the model answers because GPT-four knows what the model answer should be. Remember it came up with a question and the answer using all the information it could get from the descriptions and from the bounding boxes. Okay. And that's the kind of the genius here is that when they built the LANA model, they froze the vision transformer and then they updated the language model they were using and obviously the projection matrix, which is going to align the 2. And they only did the pre training on 600,000 pairs from a captioned images dataset. And they used a very kind of simple form of their instruction question answering. So it was something like, here's a question that GPT-4s come up with about the image based on the caption. Then you show the image and then what you want the language model to do is finish with the answer, which would be the answer to the question that it came up with. And then for the fine tuning, that's when they used this really kind of complicated, more sophisticated instruction tuning dataset they came up with, which includes like multi tone conversations, questions about the images, asking what's in particular regions of the images, asking these reasoning questions again. And they were able to generate 150,000 of these things using this process. And so they used that as the instruction tuning dataset. And when they evaluated it at the end, they found that it was outperforming all of the other vision language models at the time, complex reasoning tasks over images. And they found it was also slightly better conversational tasks than anything else. So what they showed was that putting all this effort into being really smart about generating like augmentations for the instruction tuning dataset yields a much smarter language model at the end that could complete a much wider kind of variety of downstream tasks. So just because you generated them all. And so I think that was a really like smart innovation. And in the subsequent lava models, the same kind of recipe for generating instruction tuning data has been followed. Although the models have got a lot more sophisticated. And the latest 1, which is I think for a team at BiTE Dance, is called Lava 1 Vision. And that's sitting really, really well on the leaderboard, which we'll talk about in a moment. So it shows the recipe is still like strong a year and a half later and that the class of models is really competitive.
Nathan Labenz: 59:58 Yeah. It gives you a sense too for why the leading developers seem to think they'll be able to get around whatever data walls may be naturally occurring because these were, you know, these results were achieved with largely synthetic data, at least when it comes to the final margin of actually getting the thing to behave and, like, be a useful, you know, image assistant. So, yeah, this next 1 isn't so interesting. I don't know. Maybe we'll skip it. But at the time in in summer 20 22, I was fine tuning the text da Vinci 0 0 2 series of models, and they never actually released the fine tuning there. I think it wasn't very efficient, and they had other things they wanted to do with their resources. And GPT-four was was cooking, although I didn't know that at the time. But we had this kind of preview access to that that thing, and I was using it to process images in a similar way. 1 challenge I remember we had was we wanted to be able to take a video and look at or try to answer the question, how much, well, first of all, what text is on the screen? Mhmm. But also how long is that text on the screen? And for an arbitrary video, you could, like, take a still out of it and use OCR, and that's what we did. But then it was like, okay. Well, now I've got 900 frames in a 30 second video. What is the right frequency to take these stills and then OCR all of them and then come through and have the language model process? That data was so gnarly, but that was 1 of the first things where I had this experience of feeling like, jeez, I could go try to get human annotators to do this and create some dataset and train on that. But, actually, what I'm finding myself drawn to do, and I I think this is, like, actually still a pretty winning recipe these days for many things, is 10. I was like, I'll do 10 myself. Yeah. Then we'll fine tune on that. We'll have the language model do the next 100. And then, you know, hopefully, most of those will be right. The ones that are wrong, we'll correct, then we'll fine tune again. And in that way, kind of bootstrapping into something that could do this, like, very gnarly task that humans were not very good at. You know, very unfamiliar data, very sort of not not the kind of thing we're evolved to really handle. You could do it if you really stapled your pants to the chair, but it was tough. It would have been really tough to hire out with any sort of quality. It was even tough for me to sit there and do the 10 or do inspect the next 100.
Will Hardman: 1:02:42 Mhmm.
Nathan Labenz: 1:02:42 But that was definitely a moment where I was like, this is gonna be transformative because now we're hitting the point where with the the tools available, I can actually bootstrap my way into a pretty fundamentally new capability that and I can do it in a way that's, like, way faster and way more affordable than having to go out and, like, actually hire human annotators. And that was just like, if I'm figuring this out, I bet a lot of people are figuring this out, and there's gonna be a lot of new in my case, it was narrow. I wasn't trying to create a general purpose thing. But even then, it was like, it's so you know, if I can create a new capability in a few days of work as, like, a hybrid programmer, annotator, bootstrap my way into this sort of thing. If I can do that in just a couple days, like, that's how long it would take me to, like, set up probably probably would have taken longer to set up, like, decent infrastructure to collect the data and figure out where who what platform are we gonna use, have the intations done, and who do we trust to do this, and how do we, like, validate that they're actually doing it versus, you know, just filling in whatever and not caring. And it was like, boy, I can I can bootstrap my way into that with just a day or two's worth of work in many cases once I kinda got the hang of it? It was another 1 of these moments where it's like, yeah. This is gonna happen across a very, very wide range of tasks.
Will Hardman: 1:04:11 Yeah. And I think this, this, this idea of using the AI models to generate your synthetic data for, you know, training the next generation is we see it all over the place with the vision language models. So there are examples where generating synthetic OCR data, for example, in order to train them to be able to read corrupted images and know what the text is. It's kind of a classic 1. I've seen generating latex documents as well. So you generate the latex document, and so you know the text you started with, synthetically generated the latex, and now you've got a pair. And so this you know, trying to grow the datasets, and this is always very difficult, especially in the in the realm of vision language models, because you can't just deal with a single modality of data. There's got to be a correspondence between the vision components and the language components, and the correspondence has got to be good. Like as you said back in the beginning when we were talking about CLIP, like when there was a lot of noise in the data, it was only there's only so far you can go with the quality of the model at the end. So 1 of the challenges and something that lots of the teams spend their time doing is thinking about how can I create much larger, really high quality pre training datasets where I kind of know I've got a good correspondence between the visual things that I want the model to learn and the language? So I think the Lava recipe and by the way, you can get the instruction tuning dataset from Hugging Face. You can see exactly how it's built. It's there. I think it's 1 of the a really smart way, a really creative way to think about how you build out a really sophisticated dataset. And then it has this dramatic effect when you actually use it for instruction chain on the capability of the model to act as an assistant. You know, it can do all of these other things that that previous, vision language models couldn't do.
Nathan Labenz: 1:06:01 Well, we're nowhere near the end, so, I didn't expect this to be such a, you know, nostalgia fest. It'll that'll be less because I think as we get closer to the present day, honestly, just the amount of time I've spent wrangling these, like, weird idiosyncrasies has dropped pretty dramatically as the foundation models have gotten better for an application developer like me. I've been very content to, leave these sorts of weird, things in the past, and, we're you know, in the next couple of models that you're gonna get to through this history, we start to hit the point where it's like, it's just starting to work. So let's keep going, and I'll probably be doing less of this, I remember when, stuff as we get to the present day.
Will Hardman: 1:06:47 It's all good. Comes with age, Nathan. Start Time flies. That's for sure. So I just mentioned, like at the end, I said that, you know, the latest Lava model was called Lava 1 Vision. And I said it ranks very creditably on this MMU benchmark. So we should probably say a word or 2 about what that is. So MMU, it stands for massive, multi discipline, multimodal understanding, which is something of a mouthful. And I guess the easiest way to think about it is it's like the multimodal version of NMLU. Okay? So I think it's probably the most interesting and relevant vision language model benchmark for just understanding how smart your VLM is and how much reasoning it can do. So it's designed to measure explicitly 3 skills of perception. What can it see in the image? Knowledge. What does it know about what the image is showing? And reasoning. So what can it infer from the image? And the way it was compiled is by a bunch of students, of course, from various disciplines and subjects at university drawing questions from online sources, from textbooks, and even from lecture materials. And the idea is that each question that they find has to require an expert level understanding from the domain in question. You need to have that to answer the question. So they built up about 11,000 of these questions, and they ranged over about 30 different subjects. So that includes things like history, medicine, electronics, market research, music. And some of them also require sort of mathematical reasoning to solve, for example, some of the problems involve Turing transforms. Each question says something like, here's an image showing harmonic intervals in the musical score. Which 1 of these? And then you've 4 musical scores. And then it's going to give 4 options. So it always comes in fours, you have a MLU. And so the language model has just got to select. So is it A, B, C or D that's incorrect? So it's got the multi choice questions. So quite diverse, a lot required of the models to answer them. And when they released the benchmark in November 2023, the top scoring model was GPT-4V, and that got about 55% on the benchmark. So like a random guessing would get you 25% on this. The top open source model was 1 of the lava models, like what we just discussed there. There's the second model in the lava series, and that got 34%. 1 interesting development since then, I guess, is that 1, as you might not be surprised to know, is now topping the leaderboard. So in just over a year, the leader score has jumped to 78% at the moment. So o 1 is sitting a full 8 points clear of the runner-up on this. But you can see that benchmark is, I wouldn't say crushed yet, but a lot has been done on it in the last kind of 18 months.
Nathan Labenz: 1:10:01 By the time we get done with this recording, we might find a new leader at the top.
Will Hardman: 1:10:05 That is the risk because it's actually o 1 preview that is right at the top there. We haven't got, you know, who knows what's been done to a 1 preview since it was preview and now it's a 1. But yeah, it could be beaten. Also, don't have scores for Gemini 2 and and we don't have scores for the new Claude model, I think. Actually, you might revise this because I think I might have some further down actually.
Nathan Labenz: 1:10:34 Yeah. I'm looking at their leaderboard page right now. I don't know how often they are updating it. They do have a 1. They do have a 3 5 sonnet. Not clear if this is 3 5 sonnet original or 3 5 sonnet new.
Will Hardman: 1:10:46 Original 3 5 sonnet. Yeah. I actually I actually think I've I've managed to find all the scores for those models actually. So I can tell you what they are later on. But anyway, yeah. O 1 is standing top. So what's interesting about that is when the benchmark was first released, the team who produced it actually looked at asking text only GPT-four to answer all of the questions. What they would do is they'd extract any text they needed from the images via OCR or they get the lava model to to caption the images. And they basically give a text only model, you know, the captioning that was that was extracted from the image and the question then ask how it did. And they report a score from GPT-four of 34% on the benchmark. And that, I guess, just highlights the fact is above 25% highlights the important role that reasoning will play in answering the questions. And so reasoning is really important. And the rest of the over 34% and up to whatever the models get, you can put down to their smart interpretation of the the visual tokens and their ability to reason over them. So just a quick introduction to the MMU leaderboard. We'll come back to it because for now, we're gonna score every model on it, see how it does. Should we crack on?
Nathan Labenz: 1:12:00 Let's go.
Will Hardman: 1:12:02 Okay. So I guess the next thing to talk about is pre training with vision language models and what's been learned about that. What do people do these days? And the model we'll use for examining the pre training recipes is the QuenVL series, which is from the team at Alibaba. So this series of models has 2 of them, QuenVL and Quen2VL, 20 23 and 20 24 respectively. So they're self retention models. They follow the self retention auto regressive architecture. And they're using Quen's language model, QuenLM, I think it's called as the backbone. And they're using a vision transformer as the encoder. Okay. To connect the 2, they're using a single cross attention layer. So they're not adding many cross attention layers to the language model. They're using a single kind of standalone cross attention layer, which similar to the receiver resampler has got learnable queries. And so what they're solving for there is she got an arbitrary number of visual tokens. Can we compress it down to a smaller number? And then can we inject them into the language model decoder? This is really about, in this situation, is really about using that mechanism just to reduce the number of vision tokens that go into the decoder. If you remember, we said in the most progressive architecture, you've got to unroll all of those tokens. They become part of the attention that the decoder's got to compute. So if we minimize them, that's better. So that's what they use for connecting the 2. If we talk about the training now for the QuenVL language model, The innovation here is that they're actually gonna break the pre training into 3 stages. So rather than just doing general pre training, what they learned and what everyone's done subsequently is that actually you want to break your pre training into 2 stages and then do your supervised fine tuning. So in the first phase of pre training for the VLM, they're taking their image caption datasets and they're taking their interleaved data sort of large quantities of data. They are training the vision transformer and they're training the connector module, but they're freezing the language model. Okay? In the pre training, they're having all the images resized to 2 24 x 2 24. So they're using the kind of natural resolution of the vision transformer. Presumed with the design, so you've got not that much detail in the images, but you're able to process a lot of them. The vision transformer is, of course, small compared to the language model, so it's okay to untreeze that. And the cross attention module, again, small compared to the language model, it's okay to untreeze that. So that's the first pre training they do. So the innovation is to add in a multitask pre training step here. And the idea is that for the second phase, you're going to unfreeze the whole language model. You're now going to allow the images to be a larger size as well. So in the first training step, they were 2 24 x 2 24. Now they're gonna be sized at 4 48 x 4 48. And the vision transformer is fixed, of course. So this what this means is we're gonna split each of the images into 4 tiles like this. Okay? So we've got many more visual tokens coming in to the second phase of pre training. And by multitask, they're also gonna be adding in synthetic OCR data, and then they're gonna create a visual grounding dataset as well. And so the idea here is to have a dataset where they've constructed lots of bounding boxes and references for objects in the image. They're trying to do this at scale with a pipeline that's going to build out this kind of second free training dataset at scale with bounding boxes in it, with references in the text, what's the bounding boxes are pointing at. And then they go add in, again, visual question answering datasets. By the time they started training the the QuenVL model, there were a number of kind of visual question answering or document question answering benchmarks and fine tuning datasets that have been released. And so what they did is just and some of these are of considerable size, 10, 50, 100,000 images in each case. So they actually added these to the pre training data set. So now they're representing much greater task diversity in the pre training mix, slimming down the size of it somewhat. They're also adding in text only data. And the idea here is because they're going to unfreeze the language model, they're going to be mucking around with the attention mechanism now. And so they need to keep that text only data in there to kind of preserve text only performance. So the multitask pretraining, it's bigger than fine tuning. It's smaller data set than the original pre training data set. And we'll see this theme again that because the multimodal data set is scarcer, like pre training like this, first on your low quality data, then on your higher quality data, and then finally taking a much smaller, like supervised fine tuning datasets, which involves a lot more kind of manual augmentation of the images and like using a self instruct process to kind of come up with decent prompts, is the way to do it. And that actually for the QuenVL team produced a really, really strong vision language model at the end. Quen 2, which is the latest 1 in the series, is sitting just behind the leading models from OpenAI, Anthropic and Google on the MMU, but it's sitting above pretty much all other language models. The small models are all open sourced. The 72B class, which is their leader model, is available behind an API, but they do say in a paper that they plan to release it at some point. Okay? But I thought that's it's an interesting model because they kind of really broke down this pre training process into 2 parts. They mixed in much more kind of diverse data into the second multi task pre training and had a really dramatic effect on the capabilities of the language model at the end.
Nathan Labenz: 1:18:11 So let me just try to summarize the narrative of the training of a model like this. You start with a language model, then you throw your sort of high volume but low quality or, you know, mixed quality data at it, and that is the vision language pre training step, which comes after the original language pre training step. And the main purpose of that is to sort of get these things on the same page. Right? Like, we at least need to sort of Yeah. Sort of bring the latent spaces together. Once that's working, then you say, okay. Now these things are and I guess why wouldn't you wanna change the language model at first? Because, basically, I guess you have a language model that you're at least reasonably happy with. And if you're doing back propagation through the language model, you're like, well, I don't necessarily know what's gonna change there, and I don't want to be changing things and potentially losing capability when I I kind of know, like, what I need to change. What I need to change is the part that is mapping the images into the language latent space. So do that first, get to a decent place, then open up training of the full model. Now it's like, okay. You guys are generally working well together. Now you're all the sort of constraints are off. Now we're gonna back propagate through the entire thing. And the I think the interesting detail a couple interesting details there, but 1 was definitely the need to continue to mix in standard text only stuff because, again, you don't want to be over indexing on this 1 particular task type that won't necessarily I mean, what's nice about these things is you they're super general. Right? So you don't have to give them an image. You still want them to be able to work as normal. So you gotta mix that text only data in as you do this phase, but this is where they really sort of cohere or anneal or whatever is the right word into a single system that's all been end to end trained together. And then, naturally, the last step is the dataset's not given, and that's certainly been a very common theme outside of vision too. It's just that, you know, this sort of preference data or instruct data on which a lot of the frontier models are trained is highly proprietary technology that is expensive to generate, from from a recent episode that I did with, Nathan Lambert who who studies this post trading stuff deeply. 1 of the major takeaways from that conversation was him saying, in the absence of a frontier model like a GPT-four that we use to generate the data that we then turn around and use for instruction tuning, we would have no way to get the volume of that quality of data that we would need to do this. I've probably referred back to that on, like, half of the episode since because it's, I think, a really interesting data point for where things are going in terms of, like, as they start to clamp down on reasoning. Of course, we've now also got Google's thinking model that is sharing its reasoning. So and Chinese ones too that are sharing their reasoning. So the final chapter by no means is written, but it's really interesting to see how that instruct that final phase of training, the data that powers that has to be so high quality and is so expensive to get and therefore so valuable that it's typically not released meta for all their, you know, openness is also not releasing that kind of data. And so people are currently left to, like, try to generate it with GPT-four if they wanna do something in the or whatever in the wild. But what is the future of that? Is that still gonna be a viable option? Maybe with Gemini, you know, showing their reasoning traces, but, you know, maybe not. We'll see kind of how the the dynamics evolve. But, yeah, I think that's good, and it is remarkable how I I always marvel to it. Like, Chinese companies are not far behind. You know? I I think I don't know if you have a perspective on this.
Will Hardman: 1:22:29 VLMs, in fact. Yeah.
Nathan Labenz: 1:22:33 Yeah. Well, I don't know if now is the time where you wanna maybe do this a little bit later, but I I'm interested to hear your thoughts on leaders versus fast follows versus you know, certainly, I think we in the West, you know, a couple of very broad terms, the broad we and the broad west seem to be, in my view, kind of overconfident about just how much of a lead we, quote, unquote, have relative to Chinese researchers. Even on some of these earlier papers that we've been discussing, you know, there's an awful lot of Chinese names on papers that are coming out of Western institutions. So that's a whole other dynamic here. But, yeah, we can either put a pin and and come back to this, but I'm interested in sort of how you handicap this field and and sort of how you think, like, how we should even determine. You know? I mean, the Chinese companies are definitely more open, but it seems like, typically, I would have said your OpenAI's and Google seem to get there a little bit first, but they're not open. So if you were to say they're the leaders in open models, I would say, yeah. That seems pretty Yeah. Pretty apt leader overall, including the proprietary ones. I don't know if you would, you know, say the same or see it differently, but I I'm interested in how you think about that head to head.
Will Hardman: 1:23:48 So we can answer that now, and then I'll offer a couple of comments to your observation about the high quality data in in pretraining. So the next model we're going to look at is the InternVL model. And again, this comes from an organization called the OpenGVLab, which is based in Shanghai University. Okay? And it's probably the leading open source model. And the story behind the intern VL series has been 1 about how do you scale these things up? How do you make them bigger and bigger and train efficiently? And they're looking at efficient training and they're also looking at larger models. And 1 thing I think is quite interesting is that all of the top open source VLMs are kind of hovering around the 70 to 80,000,000,000 parameter mark terminal size. The top proprietary models, we don't know, right? We don't know how big they are but bigger than that, right? Maybe an order of magnitude bigger than that. The latest model that the OpenGVLab released, they looked at how efficiently they could train. And they said they ended up training on 120,000,000,000 tokens, I think, of mixed data. And then they said this was very efficient because as compared to the QuenVL model, which we just looked at, the latest Quen2VL, this had trained on 1,500,000,000,000.0 tokens. Shortly after they released the model, they released a dataset which housed 1,500,000,000,000.0 tokens in it. So it's 1 of the largest out there. So you can see already that they've gone to a 72,000,000,000 parameter model class. They trained on 120,000,000,000 to get there. The dataset they just released is 10 times that size. So they can see that my guess would be they're planning to scale up very quickly and get to a much larger model. Since they already have the top open source model and it's pretty competitive with everything else out there, I'm really interested to see what they come up with. And this, of course, is a, you know, it's a team from a university, which is super impressive, like, without the enormous funding behind it that some of the front end labs have.
Nathan Labenz: 1:26:03 Now when you say top vision language model, is that an you?
Will Hardman: 1:26:08 Yeah. So sorry. I'm being lazy. I'm talking about just you, which is my benchmark of benchmark. We we should probably talk a bit later about a couple of the other benchmarks, which are really interesting. But is kind of the big 1 in the same way that MMLU might be the default benchmark you showed when looking at language models. Yeah.
Nathan Labenz: 1:26:31 Yeah. Okay. Cool. My kind of rough understanding and not necessarily rule of thumb, but I remember LAMA too was trained on 10,000,000,000,000 tokens. And I've always kind of rounded to say it seems like the multimodality comes at, like, another 10% cost. Like, it's another 1,000,000,000,000 typically. Do you think that's, like, a good intuition? I mean, this intern VL 1 seems to be notably significantly less than that. It's like 2 orders of magnitude difference between the original full pre training and the image portion of training. But what would you say is kind of the normal is this in fact an outlier in terms of how small the the dataset is?
Will Hardman: 1:27:19 I think there's a lot of normal because what's happening is the dataset's getting much bigger now. So let's say at the start of this year, so the biggest datasets, multimodal dataset you could train on would be the Leon, right, which is 5,800,000,000 images with text captions. It's been filtered for quality. So there should be high quality captions and they're all extracted from the common crawl. So there's a German organization that produced this, I believe. And that's, I think, is the largest kind of image caption dataset that's publicly available. Okay? But just in the last few months, we've seen an interleaved dataset called Mint, which has been released by it's a multi contributor team, but Salesforce were behind it. So that's 1000000000000 tokens, that 1. And it includes not just HTML, but it includes PDFs, archive papers, things like that. And the OpenGV Labs, who were the the team that reduced the in turn BL model, have just released data they call Omnicorpus, which is again another interleaved data set. It's 2,200,000,000 documents sourced from common crawl dumps. They say it's got 8,000,000,000 images in it and 1,600,000,000,000 text tokens. So those are just much bigger than, you know, anything that was previously available. So I I would say you're probably about right now by thinking 1000000000000 tokens is about right. Organizations like Meta do have access, you know, and and when we talk about the LAMA 3 d, we see that that is Russia, heard of the token companies for division division model there. But for open source researchers, the last few months have really seen the arrival of these huge interleaved datasets, which has really jumped the pretraining dataset size that's available.
Nathan Labenz: 1:29:12 Scaling's a hell of a drug.
Will Hardman: 1:29:15 Exactly. Okay, so we've looked at the Quinn VL model and we've looked at the multipart pre training stage where we can use our lower quality dataset at the point where we're training the vision transformer and the cross attention layer. And we don't want to muck around with a language model at that point because, you know, that's been heavily trained in the past. It's doing great, thanks. We don't want to mess that up. So we don't wanna use low quality images and captions and be training that thing. So we just trained the vision transformer and the cross encoder. So when we come to the multitask retraining and put a lot more attention and care into the dataset that now we're going to allow ourselves to train the language model. And that I think was just in response to the you made earlier about why do this or the question about why do this in multiple stages like this. Yeah, we're going up the quality scale, down the size, and unfreezing more parameters as we go. And that recipe just works really well for the vision language models. I guess the last 1 for now that I wanted to cover is the Intern VL series from the OpenGV Lab And this is a team from Shanghai University in China So 1 of the challenges that's facing particularly open source research is building vision language models is the training cost Particularly when you have to take a large model, untreeze the parameters and fine tune it or do continued pre training because you're now introducing this extra modality. So in a series of 3 models, or 4 models actually, they've looked at some ways that they can improve the capabilities of the open source language models. 1 of their papers was in fact called How Far Are We to Closing the Gap? So that was for their 1.5 model. But I'll just touch on each of them, kind of 1 after the other, because I think each of them introduces something really interesting to the picture and tells us something about where vision language models are going. So the kind of first VLM, which is called in turn VL, they observed that everything today is we've been using a vision transformer that's been relatively small and has also been pre trained separately from the language model that it'll eventually connect it to. So if we started, for example, with a CLIP that's so 1 that had been used in the CLIP model, It's of course been aligned to a language model encoder, but it's a different language model to the 1 the decoder will eventually want to connect it to. So what they did is they started with a fresh vision transformer and they scaled it up. Theirs is 6,000,000,000 parameters, which is large for vision transform. Right? So the ViT H, ViT Huge, have around 600,000,000 parameters in it. And I think the biggest of the standard vision transformers is like the ViT G, and that's about 1,800,000,000 parameters. So this, again, is several times that size. And what they do is they conduct a fresh kind of contrasted pre training of the model. They use a frozen LAMA 7B, like original LAMA as a decoder. Okay? And what they do is they take In the same way you would train a CLIP model, you take images and text pairs, and you start to feed both of them into each the text into the text model, the images into the vision transformer. You then take the hidden states from your LAMA. You can then take an average over that embedding. That's going to be how you embed the text. And then at the end of the vision transformer, you're going to take the states from that and you're going to, for example, pull that somehow. And then the exactly easy to do with the CLIP model, you're gonna do a contrasted pre training step. Right? So you're gonna try and get the correct caption pairs to be similar, the old ones to be far apart. So not so different, like, to to CLIP from several years back. It's just we're using a decoder now, and it's a decoder, it's alarm is 7B. It's gonna be much more similar to the language models we then want to connect it to in our VLM. And we've also just scaled up the size of the vision transformer. Okay. So that was their first innovation here. And what they showed is that this leads to a really high quality and really well aligned vision transformer. And what they could do is they can actually forget about the lava model that they used for the contrasted pre training. And they can connect it to a totally different language model when they build a VLM and it works really, really well. Okay. The first innovation, just train the vision transformers from scratch using something much more similar to the language model they're eventually going to connect it to when you're doing the contrasted pre training. Cool. That was the first internal VL. The second 1, the 1.5 model, they looked at 1 of the well, image resolution. That was the big question there. So we told way back in the beginning about, you know, images don't just come in 2 24 x 2 24 squares, you know, or 4 48 x 4 48 squares. They come in many different kinds of resolution. So how can we try and, you know, if we've a higher resolution image, how do we try and get more out of it? So what they did is they developed this strategy called dynamic high resolution. What this is, it takes an image that could be of an arbitrarily high aspect ratio resolution, And they segment it into tiles of a fixed size, 4 48 x 4 48. Right? And the number of tiles that they use are gonna be based on the aspect ratio and the resolution of the image. Okay? So they try and match the tiling configurations, by 4, 4 x 2, 1 x 2. We try and match that to the image itself in its natural resolution. Okay. Then I'm going to encode each of the patterns from the larger image separately, and then concatenate a thumbnail of the entire image to the end of the sequence. So now you've got your thumbnail and you've got all of your patches of high resolution, great big long set of visual tokens. In that point, they've got too many visual tokens, and so they use something called a pixel shuffle, which is just a strategy for trying to compress that down. And the way they do that is if you imagine you've got a patch from a visual tensor of an image, it's got the width, the height, and the depth. 1 of the things you can do, obviously, the number of tokens you're going to get out of that at the end is determined by the width and the height of the patch. So what they can do instead is they can just resize that so that there is there's more going to the depth dimension of the tensor, and then they're able to split it up into fewer patches. And that's just called the pixel shuffle strategy. And because this dynamic high resolution, like, ends up with so many tokens, that was the way to squeeze it down. So you use the pixel shuffle strategy. And, like, quite a few of the latest VLMs have done the same thing. So the QUEN 2 VL does the same thing, does now dynamic high resolution. But this is quite an interesting innovation. Now you can essentially process images at whatever the natural resolution is simply by generating more tokens. And, of course, if you're using a self attention or decoder only architecture, you don't worry about whether you're putting in a 100 visual tokens or 1000, except for the expense of having to unroll them in the decoder. There's no kind of harms. You don't need to have a perceiver resemblance that somehow squishes them all down to the same dimensionality at the end. So that's kind of the innovation from the the 1.5 model for internal VL. And
Nathan Labenz: 1:37:11 I was doing I was searching for something, and I would just wanted to flag that while we don't know too much about how a GPT-4V works, we can look at pricing, and that gives us a pretty good indicator that it is probably very similar under the hood because you can go even just on the OpenAI pricing page and click the low resolution checkbox. And then what you see is 75 tokens are your base number of tokens for any image. That's the minimum you can get. That would seem to correspond to the thumbnail in this, last scheme. And then if you uncheck the low resolution box and start to increase the height and width, what you see is that it starts with 1 tile. And the max, I believe, a tile can be is, like, 5 12 x 5 12. Once you get over either the height or width gets over 5 12, even if the other dimensions stay small, now you're into 2 tiles, and you can still continue to get charged those 75 base tokens. So it seems like they are probably doing something under the hood where it's like, yep. You're always gonna have that full, image as a single thing in low res. And then the question is how many higher resolution tiles
Will Hardman: 1:38:31 Yeah.
Nathan Labenz: 1:38:31 Are you gonna have? That's gonna depend on how big the image is that you feed us. And, basically, you see this exact scheme reflected in the OpenAI pricing structure. So interesting. Yeah. I wanted to this is probably on me because I was a little bit confirming that as you were describing it, but can you tell me the pixel shuffle thing again? I didn't quite grok it.
Will Hardman: 1:38:56 Yeah. So the explanation I gave was the best of my knowledge because I didn't delve into this too much. So, but basically you have a height and a width and a number of channels in like any representation of an image and the height and the width determine the number of tokens you're going get out at the end. As the idea is, I just reshape the tensor such that there's more in more in the depth channel? And then we're gonna end up with fewer tokens at the end.
Nathan Labenz: 1:39:27 So in other words, if my, if I go back to the OpenAI pricing thing, if I create a tall but narrow image, if it is if a if a single tile could be up to 5 12 x 5 12, and I have a 5 13 by a 150 image, that can fit into that space, but in its natural orientation, it doesn't. And, basically, what you're describing here sounds like a way of sort of reshaping that so that it kind of fits into the space, which I would assume under the hood with data augmentation and kind of I mean, there's a ton of that kind of stuff, right, where sort of weird I mean, the from the first, right, of just putting everything into the same 02/24 by 02/24, there's a long history of these sort of, like, programmatic manipulations of images to put it in some form, which might be quite strange from a human visual system perspective, but which ultimately probably makes the AI more robust. And in this case, also, you know, demonstrates that you can save tokens, save money, save compute all at the same time.
Will Hardman: 1:40:44 Yeah. I mean, as as best I understand, it's it's about just reshaping the tensors themselves for the ease that you've encoded. So you're actually shifting stuff from the x and y dimension to the depth dimension. And I it felt to me when I was reading about it and it was like similar to what goes on in like a U net, you know, where you're actually just reshaping the tensors again and again, making them deeper and narrower, if you like. You're not actually losing information. You're just kind of adjusting where it is. So you come out with something very different dimensions, but you haven't actually no. If you multiply the dimensions out, it's still the same size. I guess the last of the in turn VL models to look at is the latest 1, which is 2.5. We've looked at how we use dynamic high resolution, so that was in 1.5, looked at how we scale up the vision transformer itself in the original 1 model, and also do the contrast of pre training using a much bigger language model. The third thing that they looked at in in in of note in the last, 2.5 is using what they call a progressive scaling strategy. Okay? So the idea is to to try and train efficiently on a large number of tokens. And what they figured out is, could they build several classes of model, just built 7,000,000,000 parameter version and then like a mid size model and a 78,000,000,000 parameter 1 at the end? What they did is they aligned the vision transformer to the smaller language model backwards. Do the training process with a vision transformer and a smaller language model. And then they swap the smaller 1 out, may introduce the bigger, you know, the next grade up language model and then continue the training. And then they swap that out and they bring in the biggest 1 and continue the pre training. And what they find by doing this, so progressively increasing the size of the language model backbone during pre training is that they reach convergence like quite early on in the training process with a smaller language model. And at that point, the vision model, vision transformer has learned a lot of what it needs to learn and being aligned to this class of decoded language model. So they can swap that out and they can put the next figure 1 in and they can continue the training. And it turns out it's much more efficient to do this than it is to start with a large language model, start with the large vision encoder and try to align them both at scale from scratch. And in the paper, they reported that this strategy of what they call progressive scaling used they reckon they read a 120,000,000,000 tokens during the free training phase of the 2.5 model. And that's their nearest peer competitor, which is the Quen2VL language model, had to process about 1,400,000,000,000 tokens to kind of reach the same complexity loss. So they reckon it's a very, very much more efficient way to do it. And so there you go. That's kind of 3 strategies to use. Dynamic high resolution to how we process the images, how we're training the much bigger vision transformer, and then this kind of progressive scaling strategy. And this seems to be a winning recipe because if we look at the MMU leaderboard at the moment, the intern VL 2.5, the 78,000,000,000 parameter class is sitting just behind 1. And that means it's beating GPT-four-zero, the version from May, it's on the leaderboard, the original 3.5 Sonnets, and Gemini 1.5 Pro on the MMU. So it's an extremely successful recipe. It also seems to be and by the way, on visual question answering and OCR bench as well, which 2 other important kind of benchmarks.
Nathan Labenz: 1:44:41 That data scale of data thing is really interesting because it's not just that it is saving compute by starting with a smaller model. It's actually also that it's using something like 1 twelfth of the actual dataset size. So you're saving on 2 dimensions. And, yeah, that's really interesting. That reminds me of an episode, which was 1 of my favorites that we did with a couple guys from Microsoft on tinyLM, which was language models of this, I think, of, like, tens of millions of parameters, like, really small, trained exclusively on these, like, short kinda kid story type documents. And they looked at what do these things learn and in what order. And it was kind of like, you could see that they were learning things like parts of speech and, you know, really kind of structural elements of language first. And then gradually started to seem to have an understanding of, like, nouns and, you know, what was what and then started to become coherent And at sort of the far end of their process, they started to see, like, what I remember as micro reasoning skills, which was like, you know, the farthest they push this and, these are very, very small models, but you could get to the point where it was like, you know, Sally doesn't like soup. So, you know, Jimmy offered her blank. Right? And the earlier models would just put soup in again because it was like, well, soup appeared once. You know, soup is probably likely again.
Will Hardman: 1:46:27 Yeah.
Nathan Labenz: 1:46:27 And the at the end of their training, they would start to see these micro reasoning skills where was like, well, it's gotta be something else besides soup given, you know, the full context of what has come. I don't know that they looked at, like, a progressive scaling from those really small models up, but do you have any intuition for why I guess what I'm what I'm kind of struggling for, and maybe there is no good answer right now, but it seems like we're saying something here that is like the small model is actually learning faster. The small model is more Yeah. Sample
Will Hardman: 1:47:09 So let's imagine what we're trying to teach the models here. Right? So the same way you just described with the small language models. Okay? So there are progressively more complicated understanding and modes of reasoning that you can learn as training continues, right? And we can imagine that larger models that have more capacity to learn more of these things. But a larger model, of course, has many more free parameters during training. So if you have a lot of free parameters, it's gonna take you longer to find the right kind of basins in the gradient descent that actually represents good capabilities, reasonable capabilities and understanding capabilities. So the idea here, and I think this is why this is working, is that if you start with a smaller language model and you start aligning your vision transformer to that, there is going to be some cap on the degree of complexity of the tasks it can undertake. But because you've got fewer free parameters in the training setup, you're going to find kind of good solutions sooner. And at that point you can then use the larger of your 2 language models. You've got more free parameters, but you've already found a reasonable place in the search space that you're starting from. And so you just continue the pre training from there, right? Now you've got more capability, potential capability in the larger connected model, but you're already starting from a good place. Right? So you don't have to search as widely. So that would be my intuition as to why this progressive scaling strategy works.
Nathan Labenz: 1:48:51 Yeah. I mean, that is quite interesting. There was a recent claim out of 1 of the Chinese companies. I forget which 1 it was exactly, but they basically said that they had trained a roughly frontier class model at, like, single digit compute requirements of what they believe the leading developers in the the West, quote, unquote, the West, the head the big monolithic West had used. And this sort of thing, you know, could be a really interesting way that that is happening. So, yeah, that's a striking data point. I mean, the idea that you can do it with under 10%. Again, it's not just the that the parameters are fewer and you save compute that way, but it's a compounding savings because you're also using far fewer data points. This would probably be relative to you know, if they did QUIN 2 full size for 1,400,000,000,000.0 tokens and then this progressive thing only took a 120,000,000,000 tokens, it would be like this low to mid single digit compute. So, yeah, that's definitely really it's worth a ponder.
Will Hardman: 1:50:00 Yeah. So we've come now to the internal VL 2.5, which is the top open source model out there in the MMU benchmark. And you may have noticed that since we talked about Flamingo, everything else we've talked about has been based on this autoregressing self attention architecture. So 1 thing you may be wondering is, okay, does that mean this cross attention architecture is dead? And the answer is no. Even though most teams have opted for this kind of auto regressive architecture. Just to be different maybe, when the LAMA 3 vision models were released earlier this year, that was based, the LAMA 3V was based on cross attention model. So they used a vision trans, a ViT H 14, which you know what that is now. It's a 600,000,000 parameter vision transformer. But they, I think they also introduced some new cross attention layers actually into the vision transformer itself. So they made some modifications to it. The report given, like the report for the the LAMA3V model goes into a bit of detail about some of the modifications were made, but doesn't give you quite the same level of detail that you might get in some of the other papers covered. So we know that, for example, they modified the vision transformer. And we know also when they did, they used some very large pre training data sets. They did the same things a lot of other teams did, adding kind of machine generated OCR onto it. A lot of effort spent improving the safety filtering, desensitizing, de duplicating and quality filtering, the multimodal data sets that they use. So that was a real big thing there. They also did some synthetic augmentation of their pre training datasets. So it's kind of the same way we've seen the the QuenVL team do. So this is like adding synthetic captions, generating kind of tabular data, generating kind of latex documents. So adding a lot more of this stuff in at scale into the pre training. And then when they do training the model itself, the LAMA 3 model, they added new cross attention layers into it. And they then froze the rest of the LAMA 3 model. So they only trained the cross attention layers and the vision transformer. And that is both during kind of pre training and during supervised fine tuning. And they also did DPO at the end as well, which I think is the first time that I've come across DPO being used in the vision language models. But it's interesting that I've also seen it again recently. So it seems to be more of a thing now. So 1 of the advantages, I guess, this is that if you're just training the cross attentionalizing, you're not doing a full fine tune of the LAMA-three model. You're preserving all of the capabilities of LAMA-three and you're not risking degrading them by introducing the vision component. And this might be why they decided to do this with cross attention rather than using the self attention. If we're doing the autoregressive architecture, we've really just got that projection matrix to play with. And once we've trained that as best we can to do the alignment of the text and the images, If we want to keep improving the model, we basically got to unfreeze the attention mechanism and train that in the decoder. Well, they didn't have to do this because they were using quite a large, like a 90,000,000,000 parameter Lama 3. 25% of those parameters roughly being introduced for their, like, fresh cross attention layers. Training on those layers, that's a lot of free parameters. So they just they just did that when they when they trained the model. And the Lambda's 3.2, the the 90,000,000,000 parameter version of that, is the second placed open source model on the MMU at the moment. So it really shows that so just behind the end, ToneVL 2.5 ish model that we talked about. So it kind of just goes to show you that it actually really doesn't matter. You can build frontier open source vision language models using either of those 2 recipes. And that was what they what they showed.
Nathan Labenz: 1:54:18 Is there any performance difference or any sort of practical mean, I hear you on the like and having seen just a tiny bit of LAMA development from the inside, not really the inside, but I participated in a a little safety review project for llama 3. And, I mean, it just it was a lot of people moving a lot of different directions. It's kinda how I would summarize what was going on there. You know, amazing on some level that the whole thing comes together. I suppose that's probably always the case. But out of OpenAI, out of Anthropic, you see these sort of small focused teams or at least that's the perception from the outside. The, you know, internals of Meta were just, like, you know, felt like 10 different projects going on at once. So I could have easily understand and interpret this as being a reflection of just how much more sprawling the organization is and multiple different goals and maybe also thinking, jeez, you know, not everybody wants or needs vision. You know, we'll we'll let's create that modularity for the open source community that's gonna use this downstream as well. All those things I get. Is there anything that people should have in mind about the different architectures leading to different results, or does it really seem to be just kind of either way works and as long as you do a good job, you really can't tell the difference after the fact?
Will Hardman: 1:55:39 Yeah. So there are some there are some differences in that. There are some ways in which the architectures leads to to different results. Obviously, in the kind of on the design side, I mean, introducing the cross attention blocks adds more free parameters to the vision language model than just introducing a simple kind of projection matrix and going down the ultra aggressive route. So with a larger model like LAMA-three, there are probably enough, I guess they figured there's enough free parameters introduced by the cross attention blocks that we can train our kind of vision language modality alignment and get a really good results just by training on the newly introduced blocks. Whereas, as I've said before, like the downside of using the kind of self attention architecture is that if you are you know, if you've gotten the best alignment you can just out of whatever MLP you use to connect the vision tokens to the language model, then you've got to unfreeze the language model itself. And at that point, you've got to worry about degrading of the capabilities. So it could be that the decision was taken with ARMA 3. Like, it's a big model. We want to preserve all of the capabilities of our language model. So let's not muck around with the language model. Let's introduce these new cross attention layers and let's just see if we can align it for via vision language tasks. And if we do so, is it good? And the answer is, yeah. It was really good. Provided people a lot of attention into, you know, cleaning and serrating the dataset, which they did. And they used a lot of tokens as well, 1000000000000 tokens or so in the trailing budget. So which, if you've got a lot of parameters to tune, that just introduced, kind of makes sense. So the recipe works. There is some indication that the cross attention model is not so good for things like OCR and maybe also not for some forms of multimodal reasoning. For OCR, kind of the The reason for that might be because you need to introduce these You've got these new cross attention layers. And so you've got to use something a bit like a procedurally sampler or something else to kind of fix the size of your vision tokens so that you can actually look them up. And for this reason, something like a procedure re sampler is doing a bit of shuffling of the visual tokens at quite a fine grain. And this might be why it's affecting OCR performance. So a few teams have noted this, kind of cross attention architecture is not quite so good when it comes to these tasks that require really kind of fine grain understanding of small airings of the documents. So that's kind of 1 downside. I've also read some authors speculating that multimodal understanding, so like reasoning, is actually better in the decoder only, the self attention architecture as well. And this might it's not really no why, but it's just it seems that putting the vision tokens into this mixing them up in the same sequence with the text tokens and a decoder in your architecture. Attention mechanism just finds it easier and there's reason over that. But again, nobody really knows why. These are just 2 kind of minor findings. And I think it's probably enough to steer people in general over towards the kind of decoder only self retention architecture, which I think is probably gonna be the 1 that wins out. Then there's caveats, which we'll come on through a second, might not quite be the case.
Nathan Labenz: 1:59:20 The only other thing I can offer at the moment is I think 1 of the better AI podcast episodes of the year was from latent space where Swix had previously and now once again of Google, but with a sort of middle period where he was involved with Wrecker. I hope I'm seeing that right. And his take was basically that some of these architectures are a legacy of the fact that they were originally different teams. And and that Yep. You know, again, probably plays out much more at, like, a Microsoft or a Meta or a Google where they had for a long time, you know, an an organizational architecture or hierarchy or whatever that had people focusing on different modalities before the great unification of all architectures showed up. And some of that organization persists even when, you know, there there now is a sort of unification of or at least potential unification of the architecture. And so, yeah, you can maybe see some of these echoes where it's like, the language model team, you know, is moving on to the next thing, and now you're kinda taking the baton on this. And, you know, this this architecture is friendly to that, but it does seem hard to imagine. And I know we've got, you know, joint pre training coming up not too, much deeper into the agenda. It does seem like at some point, the bitter lesson has to come for this. Right? I mean, there's no no escaping that forever, presumably.
Will Hardman: 2:00:48 Yeah. It does feel like, you know, the LAMA 3 d model does feel very different to everything else that's come out of meta or fair in the last couple of years. Like I say, they're focused a lot on kind of, like, early fusion architectures, which we'll talk about in a minute. This does feel like a bit of an odd 1 out going through the kind of cross attention approach. And not just an odd 1 out given meta's research, a bit of an odd 1 out given all of the models that have come out since the last year or so, where they've really been tending towards the autoregressive architecture. Like I say, it could just be a feature of wanting to preserve the performance of the Lama 3 on language modeling tasks just by introducing cross attention layers and not having to muck around with the, you know, the models already perfectly well fine tuned self attention mechanism.
Nathan Labenz: 2:01:44 Yeah. Okay.
Will Hardman: 2:01:45 Cool. So we've covered a handful of what I think are some of the more significant models. By no means have we covered all the significant visual language models. But we've looked a bit at, you know, the importance of the, some of the things that have been learned along the way, the importance of interleaved data at scale, the importance of data augmentation in the pre training mix and then staging your pre training data as well So staging of pre training So you start simple, gradually unfreeze more and more parameters of the combined model Adding in all this augmented data of high quality as you go We've looked at that, we've looked at some of these mechanisms for processing high resolution images so tiling things and then adding a little thumbnail at the end. We've looked at the progressive scaling so that is aligning your vision transformer and your language model backbone with a smaller language model and then once you reach and kind of plateauing in your, training run switching it out for a larger 1 and carrying on and we've also looked at the importance of task diversity in instruction tuning which was shown by the lava team and just how important that is to getting your vision assistant at the end to be able to complete a wide array of vision language tasks. And where we're at now is there's this kind of these 2 architectures, this self attention or autoregressive architecture, where we're just injecting the token, the vision tokens directly into the decoder stream along with the text tokens. And then we've got this kind of cross attention architecture where we're actually injecting fresh cross attention layers into our language model. And then we're using those to kind of look at the encoded visual tokens. And a couple of recent research teams have tried to do a more systematic comparison of these 2 architectures and said, okay, which is best? And 1 of them was a team from Hugging Face And they built a series of couple of models which they call IDEFICS And although their 2 papers were building these models Really what they were doing, I think the team was doing is exploring what makes vision language models work well And that was really the thrust of their research So what what the Hugging Face team have done in their 2 paper series is try to explore what happens if you take a particular decoder and you take a particular vision transformer and then you try out both of the architectures. Okay. And see what happens. Yeah. So you've got the same training data. In other words, you're just keeping the experimental conditions the same and just changing how you connect the 2 and looking at what happens. And so some of the key findings from their research. Well, off is that if you freeze the language model and you only train the newly initialized parameters. So these would be the cross attention layers or they would be the projection matrix if you're using the autoregressive architecture. Then the cross attention architecture works a lot better, like gives you better results. That's perhaps not surprising since if you bring in some new cross attention layers, you've got more parameters there to play with than if you just have simple projection in the autoregressive architecture. But then they say, so when they try to update the language model backbone, the autoregressive architecture can perform much better. So 1 of the things they noted in, I think it's the second of their papers, is if you try to do a full update of the attention mechanism in the language models, they discovered they had training instability. So it's really, really hard to get the training to work. So they just switched to using low rank adapters and there's no issues. They were able to update the language model attention mechanisms. And in that case, the auto aggressive architecture was performing much better. So that's interesting. Perhaps unsurprisingly, if they increase the size of the vision transformer or increase the size of the language model, both of those lead to a better vision language model. But if you had to pick 1 for a fixed parameter count, they say you get more bang for your buck by increasing the size of the language model component than you do increasing the size of the vision transformer. So there you go. 1 other finding and we have kind of referenced this a lot. If you do add a perceiver resampler, which you can add in both architectures, something like that is necessary in the cross attention architecture because you've got to fix the size of the lookup vectors that you're performing cross attention at 1 But you can also have something like that in the autoregressive architecture And the reason you might want to do that is if you want to reduce the number of vision tokens that were actually being unrolled in the decoder. So you could do it for both. And they obviously find that if you introduce a procedural sampler, it does speed up training, but it doesn't necessarily have a positive impact on, performance in the end. So that's interesting as well. And finally they show that if you use the interleaved image text documents which Flamingo team and other teams have found to be super important. They performed an ablation where they left those interleaved documents out and they found it had a dramatic effect on performance of the model at the end. And that's in particular adding interleaved image text documents like this seems to really benefit few shot learning at the end. Those are some of the conclusions from their IDFX series of papers. And they're not the only ones to have a look at this. There's a recent model called NVLM that came out from Nvidia, Nvidia, a few months ago. And there what they did exactly the same thing. So they trained 3 different variants of vision language models. Well, actually 2 initially, 2 variants initially. They used a common backbone. So they used the language model from Quen. So that's the same 1 that's used in the Quen VL series. And the vision encoder, they used the intern vision encoder. So we talked about that earlier. That's the vision encoder at 6,000,000,000 parameters. So entirely new kind of trained from the ground up along with a decoder. So they train this at a larger scale with a decoder transformer to see if they get better performance from the vision transformer. So those are the 2 components they used by NVIDIA. So they denote the 2 architectures, D for the decoder only version and X for the cross attention version. And they compare them both. And they discover after training for a certain number of flops that the decoder only version has got the best multimodal understanding, the best reasoning, reasoning over images, and the best OCR performance. But they also note that the cross attention version was much more efficient to train. The reason for that, and we've kind of mentioned this earlier, is because you have to unroll the full sequence of image tokens in your decoder and apply the attention mechanism across all of them if you're training auto regressively. So it's perhaps unsurprisingly, you get lowest training throughput. So that's interesting. They report that the Perceva resampler affects OCR performance. So negatively, negatively affects it. And the thinking here is the Perceva resampler, it's the way it does resampling. It's probably shuffling some of the information in the fine grained kind of spatial dimension. And that does seem to be hurting tasks like OCR, which require a very kind of high resolution view of the image. And that's their hypothesis to what's going on there. So I mentioned they did 3 architectures and this is because the NVIDIA team then looked at, well, what if we did a hybrid of the 2? So what if we had cross attention and self attention? So the idea here is trying to make it more efficient to train the model. And that is by removing all of these kind of high resolution image tokens from needing to be unrolled in this coder. So all of the high resolution image tokens are now going to be presented to the models through the cross attention mechanism. But they take the thumbnail to remember if we're dealing with high resolution images, we typically tile the image, encode all the tiles to make the stream of tokens, but then also include a thumbnail, an overall view of the image as well. So they do inject that into the decoder stream. So this is their hybrid architecture. So it gives the self attention mechanism of the language model a copy of the image to kind of reason over. So remember this finding that the decoder only architectures seem to have better multimodal understanding and reasoning, Seemed to be something about co locating the image tokens and the text tokens in the decoder stream that works really well. So it's still got that. But the decoder is then also able to look up via cross attention, the high resolution tiles from the image when it needs to. So that's kind of, you might think of that as a compromise because it's clearly more efficient to train. And when I look through the results, you can see that the decoder only version, it does beat the hybrid version on OCR tasks still, but the gap is smaller, as you might expect, than between the cross attention and the decoder version. It beats it on chart understanding slightly. But what's really interesting is that the hybrid version actually beats both the decoder only version and the cross attention version on the validation set. Only slightly, but it does beat them both. So I think this is really interesting kind of approach, this this hybrid architecture. And it wouldn't surprise me if we saw this explored more in the future.
Nathan Labenz: 2:11:59 So is there any way in which it's like strictly better? I guess I'm I'm understanding that my my super high level summary of all of that would be, it seems like the decoder approach where the images go in right alongside the text at the beginning and get the full workup is the best performing. The cross tension is a lot more efficient, but has some relative weaknesses and some that are, like, particularly idiosyncratic, but it's easier to do. A hybrid tries to get the best of both worlds, but if I'm like OpenAI or DeepMind and I'm like trying to make the best thing I can make, Is there any argument or result here that would suggest that this hybrid approach has a claim on, you know, in any way being the best thing you could make, or is it only appealing because it has the efficiency advantages?
Will Hardman: 2:13:05 I would say it's too early to tell. So the decoder only architecture that NVIDIA put together, the d model, does win over the other 2 variants on, for example, chart understanding and OCR tasks. But on the validation split of the benchmark, the hybrid version beats both the cross attention and the decoder only version by about a percentage point, which is interesting, right? Now there aren't any other hybrid models out there that I'm aware of So it's unclear yet whether this is generally a better approach. But in this particular instance on that 1 benchmark that was their best performing model. And indeed, right now, if you look at the MMU benchmark, you'll find that the we've got the internal VL model, which is the top open source model. We've got the LAMA 3.2 vision model sitting right underneath it. And you'll find this on the MMU leaderboards. You'll find, the NVLM hybrid art architecture sitting just below those 2 in terms of the open source models. So I think it's a really interesting direction. I from my perspective, the jury's still out as to as to how else you could vary this architecture, what might be the best. So no convincing evidence that decoder only is hands down the best way to go. I think this is an interesting data point suggesting maybe there's more to the story.
Nathan Labenz: 2:14:41 Yeah. Interesting. It does I'm always amazed by how simple the transformer is. You know, that's just a recurring point of amazement where I'm like, the tangled mess that is my own brain and all the feedback loops and everything. But basically, you can get as far as we've got with none of that. So it I guess, you know, I on 1 hand have sort of a strong prior that that'll just keep being the best because it's been the best for a while. But then there's another part of me that's like, surely a more complicated architecture can work better or we would have presumably evolved in a simpler direction ourselves. So Yeah. Yeah. I don't know which 1 of those should dominate, but presumably the more complicated mean, the more I think about it, it seems like the more complicated architecture, just given how many possible versions of that there are, not to say this specific thing that has been tried here, but in general, it seems like more complicated architectures have to be better in in some way, shape, or form. You gotta find them though, and you gotta make them perform it on the compute. So those are huge advantages, obviously, that the current remarkably simple architectures have. But, yeah, that's cool. 1 other thing I was laughing at, I think you noticed at the very beginning of this section was the paper from Hugging Face was called what matters when building vision language models. And I would submit naming does matter somewhat. They came up with I d e f I c s 1 and 2 as you you had to spell it out. What is that? IDEFEX? IDEF IDEFEX. Whatever that is, it's not popping off the page to me. And I think it's gonna have a hard time in the jungle of models out there of standing out without a little bit of a catchier name. So that would be as a reviewer, I've never actually read the full paper. I would say at the title, you know, there there's a question posed that they could have perhaps answered a little bit better with a better named model, but that's just a funny reality across all of AI right now. Everybody feel like the o 3 skipping o 2 is just in some sense like totally insane and in some sense is kind of perfect for the moment that we're in. So they're certainly in good company for naming their models in a strange way.
Will Hardman: 2:16:58 Yeah. I mean, there may also be trademarking issues with o 2.
Nathan Labenz: 2:17:02 Yeah. I I heard that. Who's who's got o 2? I guess maybe they can't trademark it just because o 2 is
Will Hardman: 2:17:08 such a common thing.
Nathan Labenz: 2:17:09 Is that the idea? Called 0 2. 0, interesting.
Will Hardman: 2:17:13 Which could could be. It'd be 1 of the reasons. I
Nathan Labenz: 2:17:17 I was totally unaware of that. I was thinking that maybe because it's oxygen, you can't, trademark something so commonplace, but I guess it maybe is running the other way. In any event, it it is hilarious that they just introduced o 1 and now we're on o 3 and there is no o 2. But, yeah, somehow it does feel appropriate at the same time.
Will Hardman: 2:17:37 Yeah. There's there's 2 other things I wanted to pull out from the NVIDIA paper in ascending order of interest for me. The first is a really interesting result halfway through where they looked at some of the leading open source multimodal language models VLMs really One's a Lava model, one's an in turn VL model And they noticed that if you apply text only benchmarks if you run text only benchmarks, I don't remember which benchmarks they actually ran against the models. But you Oh, yeah. No, they ran MMLU, Math, HumanEval, a couple of others. They found that in the VLM models, there had been a drop in text only benchmark performance as compared to the language model backbone originally. So for example, the Lava 1 Vision model, whichever language model decoder they used originally, they knew what the benchmarks were across all these scores. And then it just repeated it with the vision language model and they found a drop. And they found this drop consistently amongst all the ones they tested, except for the LAMA 3 series. And if you'll recall when we mentioned the Lama 3V series, they introduced all these cross attention layers and freshly trained them, but they froze the rest of the Lama language model. So they didn't suffer that degrading. However, to kind of counter this, the NVIDIA team spent a long time building what they consider to be a really high quality text only supervised fine tuning dataset. And as a consequence of this, what they saw was an improvement on all of the language only benchmarks from the NVLM series of models. That is as compared to what the decoder they used was scoring before. So that's very interesting. Right? An improvement in the text only performance after vision language training. Possibly this could be down to just seeing the, you know, there's an additional large training training, pre training data set it's seen, which it hasn't seen before. But, you know, 1 does wonder whether there is something about the interleaving of the 2 different modalities now, which is somehow causing the transformer or the overall model to be able to reason better. So I think that's a very interesting finding and it will kind of be backed up by the fact that they saw this improvement particularly in maths. And they note that in their multimodal fine tuning data set, they had an awful lot of kind of maths questions in there, like geometry questions, for example. And they think it improved the model's ability to do numerical and mathematical reasoning even in text only form, text only benchmarks, even though this additional training data came in the form of images. So I think that's a very interesting finding.
Nathan Labenz: 2:20:40 Yeah. Let me make sure I have that clear because there's there's 2 things there. 1 is it usually the text only performance usually degrades if you just do image datasets without maintaining text only data in the mix.
Will Hardman: 2:20:57 So they fine tuning.
Nathan Labenz: 2:20:58 Did that. And then in this finding where they see an improvement in the text only math and coding benchmarks, that is that is the same thing where they are continuing to have some text only data in that mix.
Will Hardman: 2:21:18 Yeah. So the way to think about this is if you perform supervised fine tuning for a vision language model, you'll see a degradation in text only tasks. And we know this from large language models themselves. Know? If you do an additional round of fine tuning on a particular task and you want to preserve the capabilities of other tasks, you have to mix in fine tuning data just to preserve that. They're not the first team and this is not the first model where text only data has been included in the supervised fine tuning. But they seem to really go to town on this and draw out in their paper as something they really paid attention to having a large text only fine tuning data set. As we mentioned, the LAMA3D models saw no degradation, but then they froze the language model backbone And the NVLM models actually saw an increase in their text only performance And they saw this particularly on the maths data sets And so their conclusion is the introduction of mathematical questions in image format has improved the model's mathematical reasoning overall with a result app on text only maths questions. It now gets higher scores than it did before, than the language model backpoen before. I think
Nathan Labenz: 2:22:28 calls the legendary room tweet of shape rotators and word cells. It's like the language model has with the addition of the vision modality has perhaps gained a shape rotator capability that it didn't have when it was text only. Yeah. I I It certainly makes sense. I mean, if you had never seen a drawing of a triangle and only you know, and I'm kind of imagining your SAT type math problems here. If you never saw that you know, any of those diagrams and were forced to do it purely through text tokens, that would be weird. You know? There I think there's a clear reason that we do that for ourselves. So it is interesting to see a similar Yeah. Pattern popping up here.
Will Hardman: 2:23:13 Yeah. It's it's perhaps not surprising. It's just really interesting to see it actually kind of verified in the research. And it brings me back to 1 of the questions that we posed at the very start, which was to what degree is multimodal understanding important for achieving the levels of intelligence, let's say AGI that we want in the future? Well here to me is like a small data point that is suggesting, look there are real benefits to doing this. Doesn't say it's necessary. It does say it helps. So I think that's the interesting implication of the result.
Nathan Labenz: 2:23:48 Yeah. Yeah. That's definitely worth a little meditation. I mean you can imagine that that can go a lot of different directions. That that seems like it will be a huge trend. I mean, we're already seeing, of course, like, more modalities beyond just image being added, video, audio, etcetera, etcetera. I've often wondered just how far that can go. Like, are we gonna see natural language models that also get trained on, like, biological sequence data? Because that's a whole other track that I've been quite obsessed with recently where there's
Will Hardman: 2:24:23 been
Nathan Labenz: 2:24:23 all this training on sequence data. And in a way, it's really cool that there's not natural language there because I think it sheds really interesting light on how things are working when it's like, it's picking this up from, you know, all the all the things that it's learning about proteins and so on. It's it's learning those from raw data in a way that is not mediated by human understanding in a lot of those scenarios. And I think that for me has been extremely clarifying when it comes to questions of can these things learn new concepts on their own that humans don't know? It's very hard to determine that through natural language models because everything's kind of out there somewhere and, you know, what's interpolation versus genuine out of distribution, whatever. But when you see these higher order concepts emerging from pure DNA sequences or pure, you know, amino acid sequences, it seems like, okay. There's something really there that is pretty undeniable. And then I wonder, you know, does do all these things sort of converge? I mean, it seems like the global maximum probably is a model that and this may not be economic economical. There may be all sorts of reasons why it doesn't happen in the immediate future, but it like the global maximum has got to be something that is just literally trained on everything, you know, and and has the text and the image and all the way out to, like, weather data and just has this, like, very robust sort of all to all understanding. And, yeah, this is just like 1 1 little data point that suggests that that's true, but it I feel like big picture, it's hard to see how that wouldn't ultimately be the case.
Will Hardman: 2:26:09 Yeah. And and part of the story, we we kind of said at the beginning that, vision language models are really interesting route into understanding how you actually exploit the relationships between 2 different modalities to improve reasoning And some of the story we've told here is about what has been done over the last couple of years To get better and better at doing this And I don't think we're at the end of the road yet We've seen some interesting ideas so far, you know, this like this hybrid architecture from Nvidia Which suggests there may be more droplets you can squeeze from the lemon in terms of getting kind of more more efficient cross transfer of information between the modalities. So it's really interesting. And it's been a tremendous amount of progress in 2 years in this 1 area.
Nathan Labenz: 2:26:57 Yeah. This cross attention thing would also be probably the way that it happens if you were gonna try to integrate a protein language model or whatever with a natural language model. It seems like you could do the end to end thing. But for starters, you would probably grab 2 that work and try to make them talk to each other, you know, somewhere in the middle layers where all the representations are already there and you you have, like, a lot of confidence that you're working with, you know, things that have their own understanding respectively and just trying to bridge those in a useful way. Especially, you know, I can imagine too as as you have, like, lots of these modalities. It'd be an interesting question to to try to figure out, like, even if the yeah. And we and it's not even really that the the end to end thing is strictly best because this hybrid 1 is is really competitive. But I can also see just lots of reasons that you might for convenience. Right? And we talked a little bit earlier about, like, how to some degree these architectures are legacies of, team structures. And, you know, if you break that out now over lots of different modalities and you've got like a whole, you know, different universe of people working on biological models, then, you know, it might be really hard to redo everything from scratch or get the data mix right or all those sorts of things could be really hard. But if you have things that are working specialists across these domains, then I could see the cross attention approach being a really natural way to bridge them without having to kind of go back to the drawing board as much.
Will Hardman: 2:28:35 Yeah. So a term we haven't introduced yet in this conversation, but which we could introduce now is early fusion versus late fusion. And so what this is describing is at what point in your information processing architecture do the modalities come together? And in everything we've discussed so far, the answer is we've got 2 separate encoders, right? We've got a vision transformer and we've got, like I said, a tokenizer for the language model and then we're kind of, so we're encoding the 2 modalities separately and then we're fusing them in the architecture But we'll discuss something in a second where we're looking at early fusion, which is, okay, can we get 1 thing to encode them both such that the modalities are aligned right at the start of the journey through the model? And I don't want to speak out of turn because I'm not a neuroscientist, but my bet would be if you asked a neuroscientist, how does the brain work? The answer would be there are early fusion and late fusion and probably multiple integration points for different modalities of data through the information processing pathway. And it may well be that the situation that AI eventually finds itself in is that you similarly have these kind of multiple points of fusion. We've already seen with the MVLM hybrid architecture, you know, we've got 2 points of fusion there. We've got a cross cross modal cross attention lookup, and we've got an image thumbnail being added to the decoder stream. So we've still already seen the first example of that. So 1 of the trends I would expect to see is that we find, you know, we have early and late fusion going on in future architectures, but I'm definitely not smart enough to say what they look like.
Nathan Labenz: 2:30:19 Yeah. When when people talk about early and late fusion, to what degree is this a statement about the pre training process versus the architecture? I've always been a little bit confused about that because there's sort of you know, in the hybrid, the early fusion and and the later fusion are still with, like, separately trained.
Will Hardman: 2:30:47 Yeah.
Nathan Labenz: 2:30:47 Separately pretrained modules, right, that are kind of learning each modality. And then it's like, there's a question of do I wanna inject that image data at the beginning of the transformer or do the cross tension thing in the middle? But then I don't know if it's like feels like you could sort of make a 2 x 2 matrix of these perhaps where you could have like you know, I don't know about the fourth box of that matrix, but joint pre training is, like, another thing, and I'm kind of trying to untangle that Yeah. Concept from the early and and late fusion.
Will Hardman: 2:31:25 Yeah. So first off, I don't think there is a settled and canonical split in architectures where you can say, late fusion means this, early fusion means this. Let's think of it more as a continuum. I would say everything we've looked at so far is late fusion. And that includes CLIP because we are encoding both modalities separately and then aligning them. And so for that reason they are later than what you could consider very very early fusion which would be we have 1 thing that encodes both our text and our vision at the same time. So we have 1 space, if you like, right from the get go. Right. And we we will see an example of that before we finish today. Okay.
Nathan Labenz: 2:32:12 Cool. Well, let's keep rolling.
Will Hardman: 2:32:14 Yeah. So I just wanted to say a couple of words on this before we move on to a really interesting benchmark. On a couple of the benchmarks that are very important at the moment that are also have been turned into or are being used the training splits in these benchmarks are being used as part of the fine tuning data sets in lots of models we see So the first 1 is the VQA benchmark. This is a reasonable sized data set. I think there's 250,000 images in overall. I don't know what the train validation split is, But there were images taken from Cocoa So there's common objects in context and possibly from other sources too But the idea is that each image is associated with an open ended question about the image which was generated by Amazon Mechanical Turk workers And each question is supposed to require an understanding both of the vision, the language, and some common sense answers. And then you're given some, you know, if you're executing the benchmark, you're given multiple questions per image and multiple answer options per image. So they reckon there's about 1000000 questions in the data set overall. This has become very important as I said, as part of the fine tuning split. And so just to give you kind of put this in context, let's get an example from the VQA data set. So a photo of a woman who has got a pair of bananas drooping down from her upper lip like a mustache. And 1 of the questions is what color are her eyes? And so I guess the expectation is that the VLM or the vision model is going to lock onto the yellow in the middle of the screen and answer yellow, which is not the right answer. But then it also asks, what is the mustache made of? So again, this is requiring it to know where a mustache sits on the face, what kind of shape a mustache has, and then what objects are performing that role in this image. So that's kind of an example from the VQA dataset. So common sense and reasoning over images, very different notes to what's in MMU. So if 1 was looking for reasoning over images, as you know, that's the thing you wanted out of your VLM, the MMU benchmark is great. If what you were looking for is kind of an understanding of common objects, their relationships, you know, what's going on in an image, the VQA benchmark might be what you're looking at. The visual question answering. There is also a kind of variant of this called the doc VQA benchmark. Again, it's got a large training set. So it's often found in the fine tuning mix. That's about 50,000 questions that have been generated over about 12,000 images. And these have been extracted from a data set described as industry documents. Okay. So this is things like PDF scans of documents from the workplaces, charts, graphs, like tables of data, invoices, business infographics, and handwritten notes, that kind of thing. And the tasks in the benchmark are to isolate and report kind of precise spans of text from the images that answer a question. So for example, it could be, what is the number on this invoice? And then you followed by a PDF scan of an invoice. Okay. So this is an interesting benchmark and because this is the kind of thing that a lot of people want to use vision language models for, right? Is processing scans of documents. And if that's the use case that 1 really cares about, then performance on the doc VQA benchmark is the 1 to look at. And just as a final word on fine tuning and instruction tuning data sets, the Hugging Face team of the unpronounceable IDFX model vein have bundled 50 of these fine tuning data sets up together.
Nathan Labenz: 2:36:11 Much better name this time.
Will Hardman: 2:36:12 Yeah, they've called it the Cauldron, which is a great name. So the Cauldron is obviously available on their platform. And it's probably the easiest way to acquire a good fine tuning data set. The reason I mention this is because we've talked earlier many times about how augmentation of images in datasets has been really key for actually learning the alignment between the modalities. If I was starting with a task which is going to require a vision language model and I was struggling a little bit to get the performance I wanted. 1 of the things I would do is look at the cauldron. I would find a task that seems to be similar to the 1 that I'm doing. And I would look at the augmentations and the prompt structure from that particular task dataset. And I would ask, is there any way I can do augmentations on my own images? Or can I restructure my prompts such that it looks like this dataset? Because they, whether it's just an inference time or whether you're going to build your own SFT dataset, this would probably be the most informative and useful way to go about it. So that's a cheap code in my view.
Nathan Labenz: 2:37:26 Yeah, that's cool. It's a good, good tip. Shall we linger on
Will Hardman: 2:37:30 the blink benchmark for a minute? Because this is fascinating. So we talked about I've just mentioned the VQA and DocVQA benchmarks, which I think those are super important. Blink is a really interesting 1 that was produced by a mixed academic and team from Allen AI early this year, July, I think. So blink contains about just under 4,000 multiple choice questions. And it ranges over 14 common perceptual tasks. And these are tasks that they say humans can solve in a blink, but which should be difficult for VLMs. Across these 14 tasks like human performance is in the kind of mid 90% and because they're all multiple choice questions random guessing gets you just over a third. All right. The thinking behind the blink benchmark is that lots of the questions on MMU are actually about reasoning and the authors describe them as they almost reduce to a dense captioning task Right? Can you just extract a dense description of what you see in the image here? Another way of saying that is if you were to replace the image with like a rich description of what's in the image, a language model should still be able to answer a lot of the questions. And indeed when we mentioned MMU, that was actually 1 of the baselines that the MMU team created was to caption with a lava model. And then they saw that you could do much better than random guessing just from the captioning. So the interpretation of this that the blink team made is that a lot of what is testing is reasoning. Okay. And that less emphasis is being placed on the classic visual perception capabilities. 1 piece of evidence for this could be that if you look at the jump in MMU performance between GPT-four 0 and GPT-four 0 1, there's been a huge jump. And if that's all attributable to reasoning, it's suggesting that that is a lot of what the benchmark is measuring. So probably should talk a little bit about or like introduce some of these categories you know what what do the the blink authors think is meant by perceptual reasoning. So I'll cover a few of the categories. First, a couple that the VLM seems to do really well on, and then a few where they seem to do really poorly. Okay? With me so far?
Nathan Labenz: 2:39:59 Yeah. I like this because this definitely calls to mind some of the challenges that we've had with aesthetics, which I mentioned earlier as well. But at, you know, again, the way more context, it's not enough just to know the content of an image. We wanna make our users look good. And the early versions of this were basically first, they were not dense captions. They were very sort of not very informative captions. You know, you'd get, like, in the early version that there there was once upon a time when the Microsoft API was the best, and then BLIP became the best for us for captioning. But it was still you know, this is 2 years ago. We're back to the beginning of the outline, You know, so sparse. Then we got these denser captioners. Those were much better for at least getting the the relevant images content wise, but still no signal for a while on what actually looks good. And Mhmm. That has definitely notably changed. And I think these subtasks within this blank dataset that you're gonna take us through are a really interesting way to interrogate how exactly they have changed and kind of reverse engineered to some extent too, like, what the developers have done to add these capabilities when you look at these challenges. So, yeah, I I I think it's a very interesting kind of look behind the the curtain.
Will Hardman: 2:41:27 Yeah. Well, if we peel back the curtain then on the the best solved task, blink task, is what they call the art house, art style. Okay? At the time of recording, the best data that I can find is that the model that solves this the best is GPT-4.0. Okay. We don't have, I think 4 0 1 results in BLINK. Neither do we have the latest Gemini or Sonnets, I believe. So take this with a little pinch of salt when I say what was the best. But it gives you an understanding of, you know, as of June year, what do the rankings look like? So the art task. The idea is you've got 3 paintings for example, right? You've got ones from a prompt, which is a sketch And then you've got maybe 2 others from 2 other art styles And the question is which of the 2 numbers 2 and 3 seem to match the image in the prompt in terms of visual style? Okay. And if for a human this is very easy. Like 1 can look at this and say, oh, this is you've input a sketch. There seems to be some kind of renaissance painting, the second 1. And then the third 1, mean, I'm not quite sure what the style is, but it looks a bit like a sketch to me. So I'm going to say it's the second 1. And I know nothing about art and yeah, I can solve that very quickly. 4 Row does really well on this, gets about 83% and is the top scoring model. Humans are at 95% and random guessing would give you 50. Okay. So art style seems to be sold, I would say reasonably well by the current generation of VLMs. Again, another similar 1 is what they call visual similarity, which is actually sold rather well. So here you might get a series of 2 photographs and then a reference photo. And the question is you know which of the 2 photos is most similar? And in the paper they show like 2 waterfalls and then another waterfall. And 1 of them, 1 of the reference image is taken from the same perspective 1 of the images and the other image of waterfall is taken from a different perspective. So I immediately pair the correct 1 in my head. Humans indeed get like close to 97% on this. And here GPT-four turbo was the winning model at 80%. So those are 2 of the well solved ones. What I think is really interesting is the worst solved blink tasks. So these 14 categories, which ones seem to have the biggest gap at the moment? 1 of those is the IQ test. So if you've seen the kind of images you get in IQ test, know, the example given in the blink paper is 1 where you've got a simple diagram, you know, with a sequence of shapes in it. And then you're being asked which sequence seems to match this. So I've got 3 in a sequence. And then can you complete the next sequence? Pick an image of these 4, which seems to complete it in the same way the first sequence is completed. So that's if you've seen IQ tests, you've seen lots of variance on this before. Humans get this right roughly 4 fifths of the time. Okay. Random guessing in this particular area of the benchmark is 4 options at 25%. And GPT-four turbo was the best performing model with 32.67%. They're not a lot greater than random guessing. When I look at this blink task, I am reminded a lot of the RKGI questions. And I don't know if that's a lazy analogy or an ill informed analogy on my part, but I seem to solve RKGI challenges in much the same way I solve these IQ tests. Am I doing, you know, guided program search based on perceptual priors? Because that kind of makes sense as an explanation as to why I can do it in a blink and the language model is struggling. So I think it's a really interesting 1 and I think, you know, my interpretation is that this really backs up a lot of what Francois Challet says in how he designed the RKGI benchmark and why he thinks it's difficult.
Nathan Labenz: 2:45:34 Yeah. Maybe just 2 interjections from my experience. 1, on the even the well solved tasks, I would say if you're actually gonna do something like this in an app, the way you ask definitely still matters if only for avoiding unnecessary refusals. Like, I I found that GPT-four o and and Claude, you know, 3 5 probably similarly really doesn't wanna tell you you're ugly. So and that's, you know, presumably a reflection of its reinforcement learning from human feedback and it's, you know, Claude's virtue ethics. Right? It's it's trying to be a good friend to you. So it doesn't, it sugarcoats sometimes. If you say, like, you know, is this image an attractive image, for example? It will sort of often hedge and be like, well, it's sort of in the eye of the beholder. So there's a couple different ways we've found to get around that. Kind of similar in some ways to, like, you know, if you want a model to talk to you about a medical question and you're like, you know, getting the sort of, I'm not your doctor. I always get around that by saying, I'm preparing for a conversation with my doctor and I wanna be as informed as possible and that it will basically let its guard down and and help you. And in these, like, image aesthetics questions, we found if we just said the the tercist, you know, rate this image 1 to 5 beauty or whatever, it will sometimes balk at it. But if we say, is this an image that a small business would be proud to put forward in their marketing? Then you are much better able to get a result. And I've also seen kind of similar things with even just pair wise type things. So, know, I took a couple selfies of myself and my kid. And then, you know, 1 of them I made look kind of a whatever contorted face that was like clearly not a great picture. The other 1 was much more normal. And just saying like, is this a good picture? It really doesn't want to shoot you super straight. But if I put both in and I said, of these should I send to my wife? Then it will say, you know, I think you're better off with the second 1 or whatever. So play around with that stuff if you are trying to get it to work. Like everything else, you know, prompt engineering is definitely still a bit of a thing, especially if you're kind of asking it to be a judge. You know, it it it's comfortable judging in some ways, and it's really not comfortable judging in other ways. Not to anthropomorphize it too much, but that intuition definitely can be helpful. On the on the RKGI thing, I was also just really struck, you know, back when that was dominating the discourse not, too long ago by how weak the even the best models were when it came to simply describing the arc images. So just to, you know, took a few screenshots right off their website. But then, man, I didn't ask it to solve the problem. My first thing was just, can you see what this is? Can you describe it? You know? And it was very not good at that actually. Yep. Not good at even the most basic stuff of like how many squares, you know, what is the dimension of the grid. I was really amazed by how weak that was. And, you know, presumably, that just reflects kind of a lack of that sort of thing in the training data, but it's still pretty surprising because it's, like, pretty good at reading tables and, you know, they can do OCR reasonably well. And you would think that it would be able to, like, count the squares, but that was really weak. It was interesting to see too just in the last couple days with the o 3, results that as far as I know, they weren't doing any image and literally just presenting, which is, you know, the actual underlying data beneath ARC is literally just arrays of arrays. Right? Mean, they literally just give you numbers and all of the sort of color representations that we've seen. On top of that are basically a gloss for humans to make it easier for us because we're obviously good at colors and stuff and recognizing these shapes when they're, like, in contrasting colors that plays to our strengths. You don't have to do that, you know, for the arc thing, and it turns out that o 3 seems to not be doing that and is literally just reasoning over text tokens. So Yep. And Yeah. Interesting. What's your theory? Would you would you have any other sort of deeper theory on why these IQ tests are so poorly solved?
Will Hardman: 2:50:01 I am not smart enough to be a theoretician, but I just noticed, like to me, it just reminds me Speculation.
Nathan Labenz: 2:50:08 Let's call it a speculation. Yeah. Reminds me so You're smart enough to be a speculator.
Will Hardman: 2:50:11 Reminds me so much of of of RKGI. The whole point behind the blink benchmark is that humans can solve this like in a snap. Right? So there's something about the kind of perceptual priors or the perceptual features that we extract as a natural part of looking at the image. That means we can very quickly answer these IQ test questions. And it seems that like understanding of images in VLMs just doesn't work the same way. So maybe you haven't got the same kind of perceptual scaffolding that we do. And therefore I can answer it very, very quickly because I don't need to do an exhaustive program search. I've got some priors which can help me zoom in on the correct rotation if you like of the image in the IQ challenge, therefore select the right answer. Otherwise I have to do some kind of exhaustive reasoning over the possibilities As you know, would say a program search So, you know, the job of priors in this case is to constrain your search space Right, so you zoom in on the correct answer very, very quickly So my interpretation would be yeah, that they're probably not understanding the kind of perceptual elements of the image in the same way that you or I would. And that doesn't mean that you can't do very well on a benchmark like this just by adding reasoning. And my guess would be that, you know, 0 3 given a lot of compute time would do a lot better on this than 4 0 which is what has been measured and simply because it can reason over the different possibilities that would be a guess. But then again, you know, whereas with the RKG ID benchmark, you're presented with essentially a matrix, you know, an array. That's the input actually comes in as an array. And so you can kind of reason over that as a series of text tokens. Whereas the VLM has got to process the image and the blink challenge. And so it's not quite clear that you get such a clean, you know, decomposition of the IQ test image into tokens which you can manipulate through reasoning in the same way. But I'm guessing gonna guess that reasoning plays a role in solving this and that you can essentially like brute force your way through problems in the BLINK dataset, perhaps by adding reasoning, but it just doesn't feel like the most efficient way to do it. And I think that's probably the point that the authors are trying to demonstrate.
Nathan Labenz: 2:52:41 Yeah. And I mean, you're not given any, in this case, you're given only the image. Right? So that's a notable difference from the RKGI where you are given something that is text token representable and the option you have the option to, you know, use images too, but you don't have to do that here. You have to confront the image and and make sense of it. Is there anything in this recent line of work? I mean, again, I don't know a lot about the human visual system and I also don't know a ton about old convolutional networks. But my general sense of the human system is that we sort of gradually as the information is being more and more processed through layers of the brain, that we're going from like very simple, you know, edge detection type things and angle detection and all these sort of, like, features, basically, up to more and more semantic features as we get to higher levels. And that definitely has been demonstrated in certain vision systems in the past.
Will Hardman: 2:53:53 They're they're labeled, yeah, that way in the human brain.
Nathan Labenz: 2:53:59 Do you think that there's something about this this sort of vision transformer that's, like, not doing that? I I I haven't seen seems like that work was a little older and the you know, obviously, paradigm has shifted. And convolutional networks also can have, like, much more engineered features where you can put these kind of specific priors into the structure itself of the convolutional whatever processing for the lack of the the right precise term.
Will Hardman: 2:54:31 That's absolutely right. And it was pointed out in fact by the eye defects team that much more work has been put into looking at language models than has been put into looking at the actual architecture of vision transformers. You're actually right. Of the things about a vision transformer is that those inductive priors that we used to code into CNNs are missing. And in fact, that's why at smaller scales probably CNNs actually do better. And this was when we first introduced the vision transformer. That was 1 of the findings from the Google team originally. Transformer takes over, you know, as the scale increases, but it's smaller scales size of model and smaller data sets, the CNNs do rather better. So there is an open question, I think, as to what should we be looking at in terms of the architecture of the vision transformers itself. Another observation that has been made, and I can't recall where from, is that a lot of vision transformers are now trained using these contrastive learning objectives. And could this be weaker than perhaps some other way of training because when we train a transformer, we do it a different way. We have a generative pre training recipe, which is extremely effective. So could there be such a thing for a vision transformer? And that's such a great question that we might actually answer it in 10 minutes time.
Nathan Labenz: 2:55:59 Can't wait. Let's keep going.
Will Hardman: 2:56:02 So I'll just touch on 1 other example of, you know, a task that's very poorly solved by current generation of vision language models in the BLINCH BLINCH benchmark. And that's called the relative reflectance task. So here, the idea is that you give the VLM a picture and you put a couple of markers on the picture, 2 different areas and you ask which point has the darker surface color or are the colors about the same? So you always get 3 answers. So random guessing would get you 33%. So in the paper they show an image of a hotel bedroom and it's got the kind of cream colored headboard for the bed and a white wall behind it but because of the impact of the light shining in through the window you know the pixels from the cream colored headboard are actually a bit lighter than the ones on the wall. However, just looking at the image, I can tell you that the headboard is cream colored and the wall is going to be white And so I know the headboard is darker. And I can answer that in a blink as they say, because my brain is doing some adaption of the images, is accounting for the effect that the light is going to have, where it's coming from and where it's shining. So these are some of the perceptual priors I'm bringing to the problem. And it turns out that the VLMs have a really hard time solving this. Humans are kind of 95% of the right answers. And the VLMs, the top performing 1 was a lava model at the time they tested. And it was doing a shade under 40% on this benchmark. So just another kind of example that they might not be doing things the same way we are. I also think that we should point out perhaps the most interesting observation from the blink paper in my book. And I don't if they explicitly mention this but if you just look at the performance tables of the different models they tested you can see they tested GPT-4V and turbo and 4 And you can see that 4O has improved in a number of the tasks, but it's actually regressed in a number of other tasks, which is really interesting. So for example, there's been a significant regression in counting. 4V was solving the counting tasks at about 60%. 4O, they measure at 49%. So it regressed in its ability to count objects in the images. It's really not clear, like, why this is. Is this an artifact of distillation? Is this an artifact of, like, fine tuning? Not sure. But it's a result.
Nathan Labenz: 2:58:32 Yeah. On this, I can only say these things are weird beasts and find similar things in other areas too. I mean, not so much on, like, major benchmarks. I don't know if this would necessarily count as a major benchmark. It's not usually, you know, 1 of the ones that they would report in kind of a headline table. Mhmm. So they don't let those typically degrade, but certainly every time there's a new model, somebody's got a complaint with it. Right? With the super wide range of use cases that are out there. Yeah. I wonder if they're even measuring this kind of thing. I mean, they measure a lot, but are they specifically, like, looking at the jigsaw score on the blink? And maybe and maybe almost by definition not. Right? Because this paper came after some of these models. Right? So
Will Hardman: 2:59:17 Yeah. June, I think. June, I think, this year.
Nathan Labenz: 2:59:20 Yeah. Interesting.
Will Hardman: 2:59:22 But counting is a really interesting 1 because on on the surface, it feels like a really simple task to count the number of objects in an image. Yeah. And, you know, across the the blink counting task, it's 1 of the kind of it's in the middle of the pack in terms of how well it's solved. They measured the lava 1.6 model, 34,000,000,000 parameter variant, leading the pack of models with 66 percent, success rate human scores like near 98 percent, in general just a 4 choice question so the random choice baseline is 25% and I actually found another data 0.1 paper called the effectiveness assessment of recent large vision language models, again from June, which was finding that a number of open source vision language models, including the latest lava at that time, 1.5, were outperforming GPT-4V on counting tasks. So this is kind of a second data when they weren't using the BLINK dataset for this. Had another kind of methodology for this. Very interesting to ask, like, why? And there's a team from DeepMind that did a bit of work earlier this year. They were actually looking at getting diffusion models to produce the correct number of instances of an object in a picture. But as part of doing this, did a scan across some of the commonly used image caption pre training data sets. And they found that there are some captions in there which do denote the numbers of objects in the images, but they said they're very, very scarce and actually possibly not enough to learn how to bind the number correctly to the appropriate features they're extracting from the image. And this might be 1 of the problems, just the scarcity of this kind of task in the pre training dataset. So it does make me wonder that, you know, a lot of times earlier we've seen the story of improving the ability of tasks, task specific capability of a vision language model has been a consequence of augmenting a data set, you know, in order to be able to train it at modest scale on that particular task. And maybe that's the way forwards with things like counting. You know, we just need an augmented data set to be added into the kind of the mix here and that might improve things. But you know, not all is lost if you're trying to train a VLM to do counting. If you look at the kind of Anthropic's notebook collection of kind of best practices for Claude, They show you how to use good prompting techniques. NODs make the Claude think through the counting task and decompose the image and then ask what it can see. And that does work a lot better. But again, it's showing you that the fact that, you know, reasoning can compensate for some of these perceptual deficiencies, but the perceptual deficiencies are there.
Nathan Labenz: 3:02:12 Yeah. Okay, cool.
Will Hardman: 3:02:14 So a couple of minutes ago, you were asking about, you know, could we do, you know is the vision transformer part of the problem here in learning this kind of rich representation of the images then you asked about could has jettisoning the inductive priors that we brought to CNN's been, you know, a problem here? And I said, well, you know, the other thing that I've heard people mention or read experts mention is that it's the contrastive learning objective that you train a vision transformer with that might be part of the problem. And actually, a team at Apple earlier this year took a look at this very question and they said, can we do multimodal pre training of a vision encoder in a different way? I'm not using a contrastive learning objective. So what they did is they took a vanilla vision transformer. Okay. And they asked if they can change the recipe for pre training it such that they use a kind of a generative training objective. So I'll explain the setup and then we'll see how it works, how they do it. So you start with a vision transformer and transformer decoder, both trained from scratch. And it's trained on a large mix of image caption pairs. The captioning is a mixture of alt text for scraping the web and synthetic captions. So for example, generated by a lava model, something similar. So the data is prepared by taking image patch tokens. So these are small snippets from the image and text tokens and always presenting them in So you've got your image tokens first and then your text tokens. Okay? Simple tokenizer in place. Training is done using prefix attention. So prefix attention is where you basically randomly mask a subset of the visual tokens, which all appearing first. So it could be all of them are masked or it could be a small number of them are masked. And then the decoder has to generate the rest of the sequence, which will include generating the missing visual tokens. Remember these are soft tokens, they're not from a code book, followed by all the text tokens. And at this point it's using kind of standards left to right attention masking. Okay. The loss is only calculated though over the non prefix tokens, because obviously you're to feed in the masked ones first. So it's going to compute the loss over the production of visual tokens followed by text tokens. The idea here is you're doing generative pre training. So you're asking the decoder to generate the missing, image tokens, but you can't use the same loss function for text and image. Okay? Because all the text tokens come from a code book. So you can do a standard cross entropy loss for the text tokens. For the image tokens, they very simply just use a mean squared error loss. So the decoder generates an image token. It's seen, you know, some fraction of the image already. It generates what it thinks is the next 1 for the next patch in the sequence. And they simply compare it to the real token and then just compute the MSE loss. So that's a generative training recipe for the vision transformer. And they're basically training the decoder and the ViT from scratch in 1 step using a pair of objectives. Recall that the idea here is to train a new vision transformer. And so what they demonstrate in the paper is that they can jettison the transformer decoder that they've trained as part of this recipe and then connect their new vision transformer trained in this way to, and I think they used a LAMA-three model to create a vision language model. They connect the 2 in an also aggressive fashion using a simple NLP, and then they train it on the Lava supervised fine tuning mixture, which we talked about earlier. And this means they can do a nice ablation. They can compare the power of the vision language model with the vision transformer created using this generative pre training recipe with kind of a drop in, for example, a vision transformer, the same size, but trained on a contrastive learning objective. And what they find is that they see improvements in all of the VLM benchmarks that they tested against, but particularly in captioning and in visual question answering. So those are the 2 they see very significant improvements in. So this is really interesting. 1 of the questions was, is it the contrastive learning objective that is limiting the power of the vision transformer element of the recipe? Answer seems to be yes. Switching to the well proven generative pre training recipe that we know works in language models works really well for the vision transformer as well. What I would be really interested to see is whether this AIM V2 vision encoder from Apple being injected into a vision language model has an effect on blink performance. I don't know if it will or won't, but I think it'd be really interesting to know if it did. I think what we're going to see is more experimentation in the next year or 2 in this space I think we're going to see the vision transformer come under scrutiny and we're going to see more really smart ways of trying to adapt and enhance it Maybe even revisit the way it works. Reintroduce some of the inductive priors that we lost.
Nathan Labenz: 3:07:53 Yeah. So can we just linger for a second more on the difference between the contrast of training and this generative training? I think I got it, but give it to me 1 more time and make sure I because this seems like a pretty important
Will Hardman: 3:08:11 Yep.
Nathan Labenz: 3:08:12 Conceptual Training
Will Hardman: 3:08:14 on a contrast objective, pretty much everything we've looked at before now, apart from the very original vision transformer, has been done with, is you want to encode your image, You encode your caption or your paired text Okay, you've got 2 encoded vectors at this point And in a contrastive learning setup you look across your batch and you say I've got this 1 true pair within my batch and I want the cosine similarity of the 2 embeddings to be high and I want the cosine similarity of all the non true pairs in that batch to be low And the contrastive learning objective kind of forces the embedding space, you know, distorts it if you like, such that you get that result. So you'll always get, you know, an image paired closely in the embedding space with its relevant caption with similar text. For this objective, we're using a generative pre training objective here. And so what's happening instead is we're prepending each example with a load of visual tokens. We're masking a bunch of them. Okay. And then we're saying, so in other words, we're not computing the loss amongst the first let's say 3 quarters division tokens. And then we're simply asking a decoder to decode the rest of the visual tokens followed by the text tokens. Okay. We're jointly training the vision transformer and the decoder at the same time. And we're just measuring its success in reconstructing the visual tokens by the MSE between near what what the true token was, next token, and what they predicted. And then we're evaluating its performance on text in the same way. So what it should be learning to do is to attend to the caption, the text that appears afterwards. It should be learned to attend to the image earlier because it's using this decoding strategy. But what they found was if you put all of the image tokens first and then the text, a lot more of the onus is on trying to learn the remaining unmasked visual tokens, tokens from the image. And this appears to make a much make for a much stronger vision encoder than doing it the other way around.
Nathan Labenz: 3:10:26 Now that original vision transformer, it was just trained purely on images, and that was just filling in masked tokens as well?
Will Hardman: 3:10:37 Yeah. The very first the very first vision transformer was actually trained as a classifier. Oh, classifier. That's right. And I believe on image net. And so, again, as the output sequence contains a classification token, and they simply took that and then with a simple linear projection, we're training it to predict which of 1 of a large number of categories the image belonged to. That was how the very the very first vision transformer was trained. But all of the language, all the VLMs we've looked at have basically used a contrastively trained vision transformer. And we talked about how that was done when we looked at CLIP.
Nathan Labenz: 3:11:15 Yeah. Yeah. So with this with this Apple approach, would you call this early fusion or late fusion? Because I'm looking at the diagram in the paper and it's like, there is still this sort of cross entropy loss and there's like a different encoder for the vision component. So if you think of the fusion question as being like where in the architecture it happens, it seems more late. But given that they're all being pre trained, you know, together at the same time, in some sense that seems like quite early.
Will Hardman: 3:11:48 Yeah. I I would agree with you. It seems like a bit of both, doesn't it? I think they call it late because there's still a vision transformer that's separate from the language model it's connected to, but the alignment between the 2 has happened a lot earlier.
Nathan Labenz: 3:12:03 Yeah. Okay. So, yeah, I like it. I don't think I have anything else on the Apple 1. And I see we've got the I wouldn't call it the final frontier, but the next frontier is next. I think these these papers are really interesting too. So, yeah. Was wondering
Will Hardman: 3:12:20 about just skipping over the chameleon 1 and just talked about the transfusion paper. And the reason I was thinking that is because I think transfusion is just so much better, like in terms of not only its capabilities, but also its training efficiency. It feels like this is just great. And it's the way that DeepSeek built their model as well. I feel like this is the recipe. But
Nathan Labenz: 3:12:49 I trust your judgment. Whatever you think best.
Will Hardman: 3:12:52 Yeah. So, and then we just, we finish up with just like looking at the Frontier Labs offerings. We'll just go through that.
Nathan Labenz: 3:13:00 Sounds good. I'll try not to derail us too much.
Will Hardman: 3:13:04 No, don't worry. We've got plenty of time in hand. Okay. So we've mainly focused today on vision language models, which have been looking at understanding images and to some extent video, we haven't really mentioned video today, but a lot of the models that we've described can handle videos because a sequence of frames from a video is not so different to a sequence of pictures. And so, you know, a lot of what you get for, you get for free, basically. This ability to understand video is a, whether you consider it a separate modality or not, it's kind of up to you. There are some video specific benchmarks. There's a video MMA benchmark that you can look at, see how well the different models handle sequences of videos. What we haven't talked about is what's been missing for everything so far is the ability to generate images. We've really looked at image understanding. Obviously the simplest way to have a VLM or an AI in general generate an image is to have it generate a prompt and then to hand that prompt off to a diffusion model and have the diffusion model generate the image. Indeed, if we look at the frontier labs today and the services they offer, this is what Gemini and GPT-4.0 were doing with image entry and DALL E respectively. We just put behind that in parentheses. Actually, seems from the original GPT-4.0 announcement earlier this year that it is a true multimodal model and it can directly generate image outputs. I mean the O stands for Omni in it, so it can generate other modalities too. But this capability has not yet been released. It's been promised but not released due to safety and infrastructural concerns. I think that's what OpenAI said. But it's interesting nonetheless. And the question is how might this be working? And there's actually been quite a lot of work come out of notably FAIR, META over the last year or 2 looking at kind of true multimodal models. And if you're interested, kind of the sequence of papers to look at is CM3, which is they call the causal masked multimodal model of the internet and this was followed by a model called CM3 Leon which is pronounced chameleon which was then helpfully followed by a model called chameleon spelled chameleon not the same thing but this was all part of Meta's exploration of kind of true multimodal models that could both input images and text and generate them both But I thought the 1 I wanted to focus on today was the latest in the sequence from Meta and it's called transfusion. In the transfusion recipe, they're actually looking at going beyond simply just, images and text, but it introduces what I think is the most promising recipe for multimodal generation as well as multimodal understanding. If we focus on the image and text part of this here, the approach is to pre train a single transformer on an even mix of image and text data. Okay, but they're going to use during pre training a different training objective for each of them. Previous
Will Hardman: 3:16:32 papers in this series or previous models in this series from Meta when attempting this had actually quantized the image tokens before they entered into the model. Now, it's probably just worth saying very quickly, what does that mean? How does it work? So we've talked before about how, you know, text tokens obviously can be looked up within the code book. They're quantised. We've used the term image token very loosely because we actually know they exist on a continuum. But they don't have to. 1 way to quantize image tokens is using a vector quantization method. If you come across the VQGAN architecture, this is 1 way it's done. The idea is you take an image, you pass it through a variational kind of autoencoder layer to get some latent vectors and you then have like a learnable code book. So you can imagine this is if you've ever studied how k means clustering or something works you're kind of learning where your cluster centroids are in your vector space as part of your training recipe So the idea is you then quantize to the closest of your quantized vectors in this kind of latent space. Maybe you've got 10,000 of them. So you encode your image token, quantize as the nearest thing, then you decode again using the variational autoencoder decoder part. And now you just perform a number of metrics to see, okay, I've decoded my image again, having encoded, quantized it, decoded it. And now I get to compare it to the original image and then run just a number of metrics, you know, calculate number of losses over that to see how close I was to my original image. And I keep changing my code book, my learnable code book until I'm getting images that look very close to what I put in and now I've got a code book that I can use to quantise any image tokens that I see So that's kind of how they were doing it previously. And they actually jettisoned this approach completely for transfusion. And they said, you know, we're not actually going to quantize any of our image tokens at all. We're simply going to pass them through a variational autoencoder part. And this kind of turns them into like latent patches, if you like. They're going to then pass it through either a multilayer perceptron or through a unit downsampling block. This gets in their latent vectors and they're simply going to use those as tokens and inject them into their transformer. Okay. So they're kind of continuous and then the text tokens are going be handled in the usual way. So they're going to be turned through a tokenizer into their vectors. And now they're going feed the stuff into the transformer. The idea is you're training using a next token prediction, but you're going to do different losses. Different losses for text. Text regions is kind of easy. We're going to handle this with a simple linear layer then use a cross entropy, the same way we always train with a transformer. But when we detect that we're outputting image tokens, we're going to process it through the corresponding U net up path and then through the variational auto encoder decoder to actually start generating an image. And then we're going to use the diffusion loss objective there to actually train that part. So we've got 2 different things going on here. And transfusion really is, if you actually look at the architecture diagram, it is like a latent diffusion model that's been pulled in half. It's got this kind of transformer in the middle. And then you've got both sides of, if you look at a stable diffusion architecture, for example, it's like that pulled apart with a transformer stuck in the middle with the text being handed and needed away. The very important thing here is how you do the attention masking when you train it. So The training objective of these are causal attention masking for all the text. If you're decoding a text token during the next token prediction, you can look at everything to the left. For images, if you're generating image token, you've got bi directional attention. So you can look at all of the other tokens in the image when you're reconstructing 1. This means every patch can attend to every other patch within the same image, but you can only attend to text or patches of other images that appeared previously in the sequence. That makes sense?
Nathan Labenz: 3:21:03 I think so.
Will Hardman: 3:21:05 So more complicated masking to set up. Look, obviously more complicated decoding regime. You need to know whether you're decoding text or you're decoding images. You've got the kind of unit VAE structure around it. You've properly here got an amalgamation of the 2 architectures. It sounds very complicated, like very complicated to set up, very complicated to make work. But what they discovered when reporting transfusion results is really interesting compared to the previous way of doing it. So actually quantizing all of your image tokens in their previous chameleon series. They say that they're producing images of a similar quality after only training for about a third as many flops which is like truly impressive so that really suggests they're on to something here In the previous series of papers, the chameleon papers, they described having real difficulty actually getting the pre training to work stably and they had to introduce a number of what they called architectural innovations which feel like sticking plasters and changes to get it to train properly. Nothing like that was reported in the transfusion paper suggesting they had a smoother time of it and then very interestingly they found that on just text to text tasks this new recipe was matching kind of the training losses that they saw in their previous series, the chameleon series at half the flops So we're getting not only better images being produced, but also better text. It sounds like it's a really efficient recipe, just rather complicated to set up. Not much more to say about it other than this recipe I think was very similar to the 1 followed by the deep seek team so that's kind of another recent model it's fairly new so late 20 24 transfusion paper but this feels like this is something we're going to see a lot more exploration of these kind of hybrid architectures in the very near future and the team did some early experiments to ask if they can actually adapt this same recipe across kind of new combinations of modality. Can they live at audio, for example? They did some small scale experiments in the paper and they suggest the recipe will work for those as well.
Nathan Labenz: 3:23:24 1 thing I'm not very clear on is why ever quantize the image tokens in the first place? I recall reading about that some time ago and I was like, but why? It just seems strange.
Will Hardman: 3:23:40 Because if if you do that, then you can simply train a single decoder transformer to produce both images and text elements. Just got a larger code book or 2 code books. And that means you can use a much simpler training objectives. You can, for example, look at the cross entropy for both of them. You don't need all this other machinery in there to do the auto encoding and then the unit downsampling and then upsampling. It's, you know, I'm surprised that when they mentioned that, you know, they achieved the same training losses a half or a third as many of the flops, I thought it was really interesting because it sounds to me like with all that other machinery, that actually there's it's gonna be much more compute intensive to build 1 of these hybrid architectures like term transfusion. So I'm assuming that is all factored in when they talk about the losses seen at the number of flops. It is it is a more complicated model.
Nathan Labenz: 3:24:39 I'm scanning through both of these papers and it is remarkable on the chameleon 1, which is the 1 that has the discrete or quantized image tokens. It is remarkable that the image outputs do look pretty good. Like, you would think that does it say quickly how big the vocabulary size is of this?
Will Hardman: 3:25:07 May say in the paper. They did yeah.
Nathan Labenz: 3:25:12 It's not that big. It's only code book size of 8,190
Will Hardman: 3:25:21 the
Nathan Labenz: 3:25:25 512 by 512 image gets broken into a 24 discrete tokens, which means, you know, they yeah. That's that's weird. I don't know. That's like you've got 250,000
Nathan Labenz: 3:25:47 pixels. Right? 500 times 500, you got 4 zeros with a 25 in front of it. So 250,000 pixels, 1000 discrete tokens. So you've got 250 pixels per token Yeah. In this chameleon thing, which
Will Hardman: 3:26:04 by 16 patches then, by the look of it. So if you take 5 1 2, by the way, 16, you get 32. Square that. You get 1 0 2 4. So 16 by 16 patch. So when you think about it, 16 by 16 pixels, and and then you've got 8,000 tokens to cover that. How many different variations of a 16 by 16 patch do I need?
Nathan Labenz: 3:26:35 I would still think a lot more. I don't know. It just seems like there's know, each pixel is 3 colors, you know, with a range of 2 56 values. So just the number of possible colors for a single pixel is 2 56 cubed. Right? And just from that alone, I would think, boy, 8,000 tokens to represent a 16 by 16 little patch would just does not seem like enough. But, I mean, it's hard to argue with the results. The images do look remarkably natural. I'm quite surprised that that works. I would I would have intuited that it would have been just much, like, more artifact y that you would be able to see these, like, you know, where these tokens, you know, come together. Yeah, I would expect you would see the seams of this. And generally speaking, I don't see them. That's quite that's quite crazy.
Will Hardman: 3:27:40 Yeah. They've they've certainly reported for transfusion that they did some evaluation benchmarks and compared it to DALL E 2 and stable diffusion Excel. And they found that they were outperforming both of those models and that they were reaching Lama 1 performance on text only tasks. So that was their 7,000,000,000 parameter transfusion model. Again, and I don't know if this interpretation is warranted from this, but it's really interesting to see such like fantastic performance. I know these are, it's more recent architecture. There's probably a lot of tips and tricks they're using in training it, which weren't used for SDXL or DALL E 2. 1 also wonders, you know, what role has this mixed modality learning played in improving the ability of the model to generate images? I'm not sure. But it's it's an interesting question given that we've certainly seen it happen the other way around.
Nathan Labenz: 3:28:42 Yeah. The image editing on this is really impressive too. I'm now switching over to scroll through the transfusion paper. And I think the demos of this that are most compelling to me are basically instruct style editing. There was an image, there was a model not geez, when was this? I guess it was almost 2 years ago now. Instruct pics to pics was the 1 that basically you could give an image and give a command and it would attempt to edit that image according to your command. And I did 1 of an ultrasound image of my son who's now a year and a half and said, make it look like a newborn baby instead of an ultrasound. And it kind of did that. Not not too bad. It was a funny experiment anyway. And yet those were limited to say the least in terms of what you could do and how good the quality was and how much fidelity it it actually had to your instructions. It was, you know, kind of all over the map. Here, I'm like, man, this is exactly what we need for the Waymark application because we're talking very precise local edits that are not changing the overall composition, not making the image feel like it's a totally different image, but doing the precise cleanup that you might see from an actual pro image editor doing it in a Photoshop or what have you. So things like you know, a couple examples here that stand out to me most. 1 is change the graffiti on the on the side of a truck into calligraphy writing. And the before and after is just amazing. I mean, you see the 1, you know, before is, like, tagged, of course, with graffiti, and then it's just like, man, it's it's perfectly in situ calligraphy that's been printed onto the side of the truck. Yeah. Examples of removing things, you know, replace 1 object with another, change the color of this thing. This is pretty
Will Hardman: 3:30:44 Pretty impressive. Yeah.
Nathan Labenz: 3:30:45 Yeah. It is pretty impressive. That is This has never been released. Right? Was it do you know why they haven't released this?
Will Hardman: 3:30:51 No. To my knowledge, none of the the series has been released. And I'm not sure why. Does wonder what image sources they used for the different models. They do say at least in some of the papers, used only kind of open source or publicly available image sets. I don't if that's true for all of them. I'm sure for everything they use. They may also they're text to text. They may also have some in house text to text kind of data sets that they used, which for whatever reason they don't want to release. But I'm not a 100% sure. But you're right. It certainly beats like the Spaghetti's web comfy UI canvases that I end up building to do image editing. Just be able to write it in a single sentence.
Nathan Labenz: 3:31:37 Yeah. You can really see the the future here, I think, and in some of the GPT-four o demos as well. Mhmm. It's funny. People ask us all the time about with Waymark application, do you use stable diffusion or Dolly or whatever? And we've actually found that those things are not very useful for our users because they aren't realistic to you know, small business wants to present itself in a, you know, positive light, but in, like, a realistic light. They don't want it to feel like, wait. This is nothing like what I saw on TV when you actually show up. So the lack of control and the difficulty of grounding the purely generative models has been a real challenge. And you've, of course, can do image prompting, but a lot of times those also haven't worked super great. They sort of noise your input image and then take it in kind of a different direction. And it's like, oh, I actually wanted something that was more like local specific, like maintain the integrity of this, but change it in this 1, you know, very specific way. And that has been hard to do. I also can imagine how there's other techniques now that are that are popping up for this too, but character consistency has always been a real challenge. Yeah. For people that are try just trying to create original content. And the way my creative team has done some really cool stuff, we did an episode. I hope we have another 1 soon, but we did an episode on basically a short film that they made with all Dolly 2 images. This has been a while. Now there's a part 2 that uses newer models and all sorts of new techniques. Character consistency was a huge problem in those, early models. Scene consistency was another huge problem. They, I mean, they came up with elaborate prompting techniques and all sorts of ways to try to get around that. And I think did, you know, a really remarkable job with what they had at the time. But when I look at this, I'm just like, man, it it a lot of it falls out of this very quickly where you can just say, you know, change this, do this, put this guy in a different scene. You know, next thing you know, you're kinda off to the races on a lot of the different things that you want to do that have been hard. So, yeah, presumably that'll be coming at some point from an API provider, GPT-four o or or otherwise, or maybe they'll finally get around to releasing this. But it is I noticed too, Lily Yu, who's a former guest, I had her on to talk about megabyte. It was called basically a byte level transformer. And interesting to see her name pop up on another 1 of these kind of continuous space transformer projects. Yeah. Cool. So this has been a fantastic, deep dive and and walkthrough. Where does this leave us now?
Will Hardman: 3:34:26 Well, maybe we could just wrap up just with a quick summary of what the kind of frontier labs are offering and kind of what's winning on the different benchmarks. So I found I had to compile this data from a number of different sources because it wasn't all available all in 1 place. So I've done the best I can, but if 1 is building with 1 of these models and you know that you want something that's well on MMU or for example doc VQA, so it's, you know, extracting information from images or maybe even if you're interested about what does well on Blink, I try to compile this into a simple table and I can just walk you through now what I think is winning in each case.
Nathan Labenz: 3:35:12 Cool. So Yeah. This is really useful.
Will Hardman: 3:35:14 So what I looked at, I looked at, the Grok 2 beta I looked at the latest version of Claude Sonnet 3.5 new Gemini 1.5 pro because I was unable to find the results yet for Gemini 2 4 0 1 preview, I could only get 1 result for and that was the MMU, but 4 0, I could get results for all of them from. And then just a couple of open source models as well. Okay. So if we look at leaderboard here and we say, okay, what is currently doing best on if I really cared about reasoning over images? And 4 0 1 is standing head and shoulders above everything else with 78% there. And if I wanted to look at what was next down from that, we would find Claude 3.5 SONNET new and the intern VL 2.5 model, which is currently available, I believe, through an API. We find those down at 70 and a bit percent each. So Gemini 1.5 Pro is coming a few percentage points below those 2. So that's kind of where we're sitting on at the moment. Be interested to see what Gemini 2 does there. But the Grok 2 beat beta is sitting at 66% on if we're to look at Yeah.
Nathan Labenz: 3:36:35 Quick note on that too, because this intern, I keep forgetting as we've gone through this, who made this model? The OpenGV lab. Which
Will Hardman: 3:36:44 is Yeah.
Nathan Labenz: 3:36:47 So it's another I mean, I think we touched on this a little bit earlier too, but it's another good reminder that the Chinese models, the Chinese labs are not super far behind. They are, in this case, right there head to head with Anthropic 5 months earlier.
Will Hardman: 3:37:03 The Lava the Lava 1 vision model is from ByteDance, but the Quinn model is from Alibaba. Yeah. And they all perform very well.
Nathan Labenz: 3:37:14 And this is not yeah. The reason I mentioned the 5 month earlier thing too is because sometimes people will be like, oh, well, they're, you know, doing the they're starting with, you know, an American thing or they're, you know, they're starting with llama and not acknowledging it or they're, you know, trading on the outputs of the American models, whatever the the sort of rationalization often is. And I'm sure sometimes that stuff is happening. But here, it is still as of now and I guess we've got, you know, caveats around like o 3 and whatever and full o 1 where not all the data points are available yet. But Mhmm. It is striking that this Shanghai AI group has 3 tenths of a percent lower than Cloud 3 5 Sonnet new a full 5 months, ahead of time. So they're definitely not, definitely not training on Claude outputs to achieve that. And that is higher than GPT-four o by just a point, but still it's like, I think it's it is very much worth keeping in mind that Yeah. It's good
Will Hardman: 3:38:16 for him.
Nathan Labenz: 3:38:17 The gap here is, like, basically 0. And arguably, you could even say if you squint at it, you could even say the the Chinese labs are maybe a little bit ahead, but I would say Yeah. Overall rounding, you should probably say they're about the same.
Will Hardman: 3:38:32 Yeah. And we also note as well that the parameter counts in their models all around the 70 to 80,000,000,000 parameter mark. Presumably, they're gonna build larger and larger. Presumably they'll get better and better as a result But, you know, lots of what we talked about earlier in the podcast about how fast the training recipes and the data sets are developing, you know, probably goes to account for a lot of this Just the more recent the model like they get better every single time because people are learning so much about how to effectively do this I think it's also interesting to look at the doc VQA scores here you know all of the models that I mentioned are doing above 90% on that benchmark the best I can find is again it's the quen2vl quenvl2 model which is currently doing 96.5%. So that's open source proprietary model. I don't have results for the new Claude 3.5 or 4 4 0 1 on doc VQA, so that's just to point that out. But that model is doing better, for example, than GRUP-two, it's doing better than Gemini 1.5 and GPT-four 0 on doc VQA. So kind of leading there. Blink is very interesting because we haven't got results for everything here but kind of at the top of the leaderboards, we've got 4 which has about 63.2%. I have seen a result that's higher than that but I've seen 3 results for it. 2 of them were at 63.2% on blink. I'm gonna go with that 1. The OpenGV Labs in turn VL 2.5 is clocking in at 63.8, so doing ever so slightly better. Gemini 61% and Claude 3.5 Sonic New at 56.5% So those are the best and most up to date scores I can find on those 3 benchmarks It's also worth just looking at the mini class here. So here I've been in kind of the flash and mini versions of some of these models. They're obviously a little bit lower down most of the benchmarks, they're smaller models, but it's interesting to know if I was to pick 1 up, what would I use? If we look at MMU, we've got results for Gemini 2 flash, which is clocking in at 70.7%. That makes it stand head or shoulders above everything else in the mini class by which I'm including 4 minutei, the intern VL 8,000,000,000 parameter. I haven't got result for 4.1 minutei. Grok 2 minutei is at 63.2%. Best bet, if you want kind of reasoning over images, would seem to be Gemini 2 flash at the moment. Doc VQA got very few results here, but the in turn VL 2,580,000,000 parameter model is clocking in at 95.1%, which seems pretty damn good to me. Interesting enough, that's exactly the same result as it gets in its full 78,000,000,000 parameter form. Blink, we're just going to finish on Blink for the mini class of models. The best score I can find and I couldn't go on for Grok for Gemini 2 or for 4 0 1 minutei, but I could find it for GPT-4.0 minutei and that's talking in at 51.9% which means that the intern VL 2.5 model is getting slightly better at 54.8% The surprise winner coming in from left field in the mini class is Microsoft's PHY or PHY, depending how you want to pronounce it, 3.5 vision model, which is a 4,000,000,000 parameter class model and scoring 58.3% on the Blink benchmark. Not doing so well on MMU, doing really well on blink, which is really interesting. So I combed the technical report for the v vision model and just a couple of interesting details from it and not enough to make conclusions on. For a 4,000,000,000 parameter class model, they used half 1000000000000 pre training tokens from the mixed pre training data set. And that's a big data set for a small model. We think about the intern VL 2.5 model, they said they trained on 128,000,000,000 tokens. The quen-two model, 1,500,000,000,000.0 tokens. But those are all many times the size. So it's a fairly large training data set for a small model. The other really interesting thing was that they mentioned their SFT dataset, which they described as a combination of datasets from a significant component of which was built in house by Microsoft. 33,000,000,000 tokens. So this is instruction fine tuning data. That's an extremely large dataset, especially for a small model. I mean, I can't recall seeing 1 that large anywhere else in the research. And they also mention performing DPO, which only a couple of the other models like ARMA3V explicitly mention a DPO step. So not sure why it does so incredibly well, but anecdotally, I have seen plenty of commentary online with people saying, wow, the 3.5 model is really good at visual understanding. So really interesting, perhaps something we should have dwelt on a bit more in the podcast. And that is about everything that we wanted to cover today. I mean, we've kind of told the story of the last couple of years of VLMs. What are we going to see in the future? I think we'll see a lot more of these kind of true multimodal models following the transfusion recipe. I do expect to see the scale parameter count of open source VLMs increase further, particularly now as we know about this kind of progressive upsizing of language model backbones work so well. We should expect to see more innovation in either pre training of vision transformers or maybe even their replacement at some point. And a continuation of this production of new fine tuning data sets that contain programmatic or human augmentations. So I would, for example, expect to see new fine tuning data sets there. What we haven't seen too much of as well is we just mentioned DPO at the very end there, Not too much exploration of the role that alignment post training can play in vision language models. So we expect to see that explored as well. And that concludes not quite so whistle stop till through the last 2 years of vision language models.
Nathan Labenz: 3:45:12 Amazing. Well, the depth of research that you put in to make this possible is outstanding and definitely much appreciated. I learned a lot from it. So as you know, that's how I tend to score these episodes for myself. And I come away definitely with a much better understanding of the various options and strengths and weaknesses and even a few prompting techniques along the way. How does this relate to what you typically do? And maybe in the last, couple minutes, just tell us a little bit about, like, your normal work and, the sort of stuff you do commercially.
Will Hardman: 3:45:49 Yeah. So a lot of this is relevant to some of the work that I'm doing. So, Verity is the small consultancy that my colleagues and I set up a couple of years back. We do a lot of AI strategy work. So before that we used to do a lot of data science and analytics strategy in my background and we've moved on to thinking about how do you develop and build an AI strategy and especially if you're an SME. So I think that's our sweet spot. Although what we do does work, think in larger organizations, you're kind of working at the department level. So we do a lot of that, but we also do a lot of prototyping work for people. Proof of concepts. You have some ideas, you know, that in your strategy, things you wanna follow, things you wanna, things the company wants to try out. So you have a very kind of structured way of performing these experiments cheaply and finding out what's easy and what's difficult. Because as you probably know, a lot of working with AI today is, you know, it's your mileage may vary. So we kind of know what the best practice is, but it's very hard to know from the outset whether you're going get great results given the data or compute constraints that your client may have. And so we've kind of developed this rapid experimentation methodology. But in some of the domains we're working on, we do some in medicine, particularly looking at medical terminologies and how they get used by language models and how language models can work with them. But also, and I've spent a lot of time looking at open source intelligence for a few clients recently And there a lot of kind of the data that we're trying to interpret is multimodal in nature. So there's lots of trying to understand, you know, how does this image seem to correspond with this claim that's being made? You know, can we infer who might be in the image or what the image is about, given that there's some surrounding text or context we understand? And so in that, you know, it's in that domain that we've certainly been working with some of the VLMs here.
Nathan Labenz: 3:47:43 Yeah. I hear a couple sort of reflections probably of some common experiences that we've had. I don't do a ton of this sort of stuff, but occasionally, you know, mostly I've done it just for my own company, which I've mentioned a dozen times already. But occasionally, I'll take on a project for somebody that asks me for help with something. And it's an interesting juxtaposition often of like and I'm sure you've found various versions of this. A lot of times you can, like, answer somebody's question really quite quickly. And I'm always reminded of Tyler Cowen's answer for when he's asked how long it took him to read a given book because he's a famously fast reader. People ask him that question and he always answers with his age. And I think this, tour through vision language models is a good reflection of how much depth and sort of obsessive quality of research has to go into the ability to then turn around quickly and be like, I think I know what to do here for your random situation. And I think we can put together a proof of concept on that pretty quickly. But that's because you've done this, like, extensive exploration of everything that's out there and have a really already fine tuned intuition for which direction to go.
Will Hardman: 3:49:04 Yeah. The way we do strategy projects relies on this a lot as well. It's like, you have to come with prepared minds. You have to come having been immersed and soaked up everything that's happening. So that when you see the you know, when people say this is the problem that exists here, you can pattern match it to something and, you know, I am sure like you have got a, like, a big archive, searchable archive like my own personal kind of rag index that I maintain at home of just everything that I ever come across papers, newsletters, sub stacks, whatever it is, sits in there. And I just try and pattern match it so that I have some grasp of, okay, this is how we're gonna, you know, suggest the options for how you might solve this problem, a, b, or c. And, yeah, you but you do need to be steeped in it, I think, in order to then spot the opportunities to use the the technique, the technology, the model, whatever it is when you actually see it in practice.
Nathan Labenz: 3:50:02 Yeah. Cool. Do you wanna tell us where we can find you and the company online?
Will Hardman: 3:50:07 Yeah. You can find the company website at Veratai, which is veratai.co.uk.
Will Hardman: 3:50:14 Veratai.co.uk. Or you can find me on LinkedIn, Will Hardman, and I am writing a fair bit of moment about AI strategy. And next year, we'll be writing about various other things and maybe about vision language models as well.
Nathan Labenz: 3:50:30 Cool. Well, I'll be sure to connect with you there and encourage the audience to do the same. This has been a fantastic walkthrough of vision language models. I know a lot of work has gone into it, but if you wanna tackle another topic like this, I would love to do it. Yeah. Now I will say thank you for this 1. And officially, Will Hardman from Veritide, thank you for being part of the Cognitive Revolution.
Will Hardman: 3:50:52 Thanks for having me on, Nathan.
Read next



